Top 30 Machine Learning Interview Questions And Answers

Machine Learning
Machine Learning has become crucial in the tech industry, changing how we solve problems and analyze data.
Machine Learning Engineer is ranked #8 among the Best Jobs in the U.S. due to its 53% growth since 2020 and a median salary of $153,252 per year.

The computer and information technology job sector is expected to grow by 15% from 2021 to 2031.
The growth is because industries are increasingly using AI and machine learning.
The article's mission is to prepare readers for machine learning interviews, covering foundational and advanced topics.
Many machine learning jobs pay over $100,000, with some offering salaries of up to $200,000.
The conclusion emphasizes the fascinating and rewarding nature of the machine learning field.
There's an expected 40% growth in demand for AI and Machine Learning Specialists, equivalent to 1 million jobs.
Staying updated with the latest trends and technologies is essential in the ever-evolving field of machine learning.
ML Defination
Machine Learning has rapidly become an integral part of the tech industry, revolutionizing the way we approach problem-solving and data analysis. In fact, it’s worth noting that Machine Learning Engineer is currently ranked as #8 among The Best Jobs in the U.S. This is due to its remarkable 53% rate of growth since 2020 and a median salary of $153,252 per year. Furthermore, the overall computer and information technology job sector is projected to grow by 15% from 2021 to 2031.
This growth is attributed to the continued transformation of industries through the usage of AI and machine learning. Our mission is clear: to equip you with the knowledge and confidence to excel in any machine learning interview. From foundational concepts to advanced techniques, we’ve got you covered. The majority of machine learning jobs pay well over $100,000, with some, like machine learning engineers, offering salaries of up to $200,000. So, let’s dive right in and explore the questions that can shape your machine learning career.
1. What is Machine Learning?
Machine learning is a subset of artificial intelligence (AI) that focuses on the development of algorithms and statistical models. These algorithms enable computers to learn from and make predictions or decisions based on data. Instead of being explicitly programmed to perform a task, a machine learning system uses patterns in data to improve its performance over time.
In simpler terms, machine learning allows computers to learn and improve from experience, much like how humans learn from their mistakes and successes. It’s like teaching a computer to recognize patterns or trends in data and then use that knowledge to make decisions or predictions.
Machine learning is widely used in various fields, from healthcare to finance, and it plays a crucial role in the development of AI applications. It’s the technology behind recommendation systems, speech recognition, image classification, and many other intelligent systems.
2. Explain the Difference Between Supervised and Unsupervised Learning
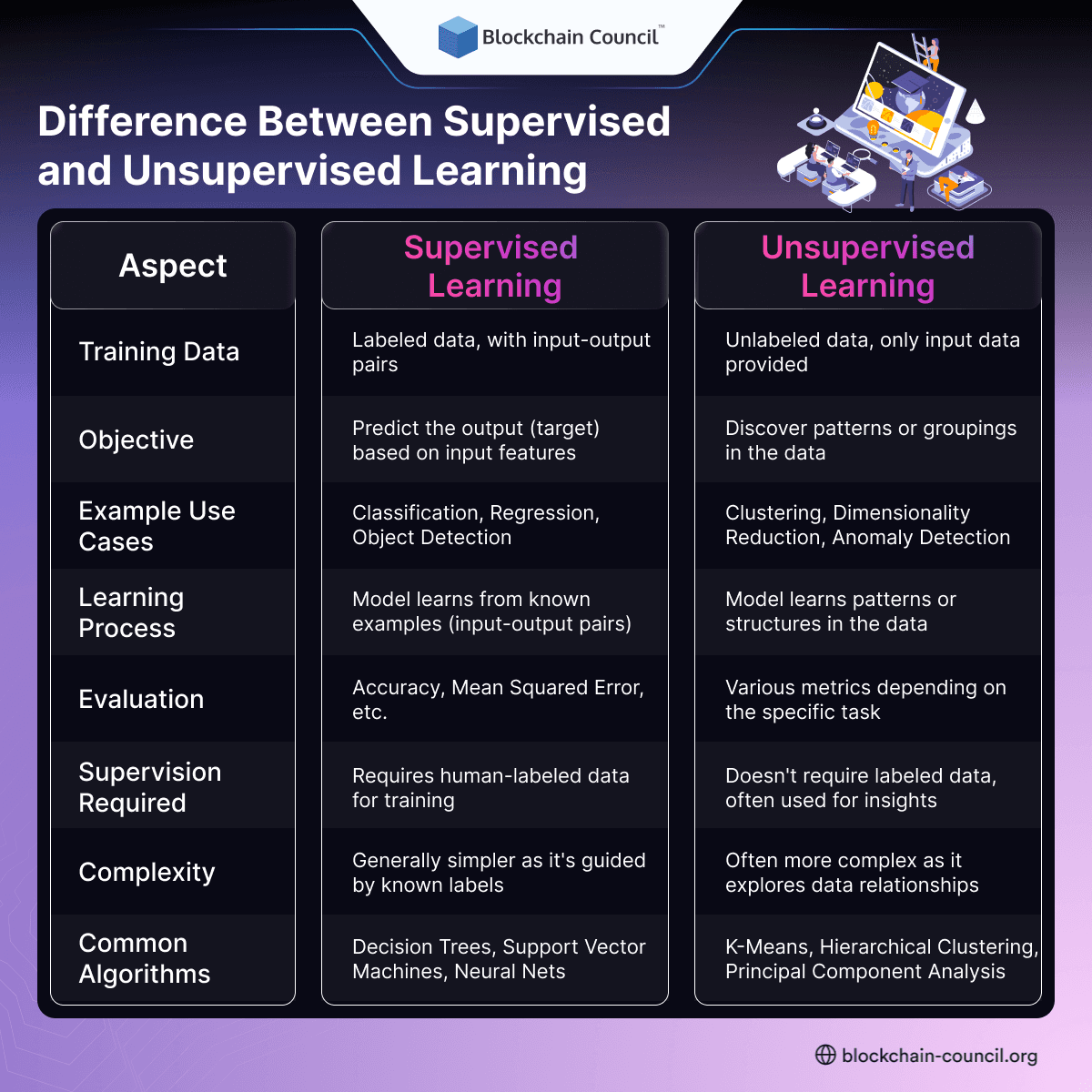
3. What is Overfitting in Machine Learning?
Overfitting is a critical concept in machine learning that occurs when a model learns the training data too well to the point that it performs poorly on unseen or new data. This happens when a model becomes overly complex and starts capturing noise and random variations present in the training data, rather than focusing on the underlying patterns.
To put it simply, overfitting is like a student who memorizes their textbook but struggles to answer questions that require a deep understanding of the subject matter. In the context of machine learning, an overfit model may give exceptional performance on the training data but fail to generalize well to real-world scenarios.
To combat overfitting, techniques like cross-validation and regularization are used. Cross-validation helps assess a model’s performance on unseen data, while regularization methods add constraints to the model to prevent it from becoming overly complex. Balancing model complexity and generalization is crucial in building effective machine learning models.
4. How do you handle missing data in a dataset?
Step 1. Identify Missing Data:
Before addressing missing data, identify where it exists in your dataset. Common representations include ‘NaN’ (Not a Number) or ‘null’ values.
Step 2. Remove Rows with Missing Data:
If only a small portion of your dataset contains missing values, one option is to remove those rows. However, be cautious not to lose too much valuable data.
Step 3. Fill Missing Data with Averages:
For numerical data, you can replace missing values with the mean, median, or mode of the available data in the respective column. This maintains the dataset’s statistical properties.
Step 4. Predictive Modeling:
Use machine learning algorithms to predict missing values based on other features in your dataset. This method can be highly effective but requires careful model selection and evaluation.
Step 5. Interpolation:
In time-series data, you can use interpolation techniques to estimate missing values based on neighboring data points.
Step 6. Domain Knowledge:
Leverage your domain expertise to determine suitable values for missing data. This approach is valuable when data is scarce, and statistical methods may not apply.
Methods for Handling Missing Data
Deletion: One approach is to simply remove rows or columns with missing data. While this is straightforward, it can lead to a loss of valuable information, especially if the missing data is not random.
Imputation: Imputation involves filling in missing values with estimated or calculated values. Common methods include mean, median, or mode imputation, where you use the average, middle, or most frequent value to replace missing ones.
Advanced Techniques: More advanced methods like regression imputation, k-nearest neighbors imputation, or using machine learning models can provide more accurate replacements for missing values. These methods consider relationships between variables, making imputed values more contextually relevant.
Data Augmentation: In some cases, missing data can be synthetically generated using techniques like data augmentation. This approach can help preserve the dataset’s size and integrity.
5. What is a decision tree in machine learning?
Decision trees are powerful tools in the world of machine learning. They are versatile, easy to understand, and widely used for classification and regression tasks.
Structure of a Decision Tree
A decision tree is a tree-like structure where each internal node represents a feature or attribute, each branch represents a decision rule, and each leaf node represents an outcome or a class label. It’s a visual representation of decision-making processes.
How Decision Trees Work
Splitting Nodes: Decision trees begin with a root node that represents the entire dataset. The tree splits the data at each node based on a feature that maximizes the separation of classes or minimizes the variance in regression tasks.
Recursive Splitting: This process continues recursively until a stopping criterion is met, such as a predefined depth or the purity of the classes at each leaf.
Classification or Regression: Once the tree is constructed, it can be used for classification by following the decision rules from the root to a leaf node or for regression by averaging the values in leaf nodes.
6. What is a neural network?
Neural networks are the building blocks of deep learning, a subfield of machine learning that has revolutionized AI applications in recent years.
Basic Components of a Neural Network
Neurons (Nodes): The core units of a neural network are artificial neurons, also known as nodes. These nodes receive inputs, apply weights to them, and pass the result through an activation function to produce an output.
Layers: Neural networks consist of layers of interconnected neurons. The input layer receives data, hidden layers process it, and the output layer provides the network’s final prediction.
Training a Neural Network
Forward Propagation: During training, data is passed forward through the network. Weights and biases are adjusted iteratively to minimize the difference between predicted and actual outcomes.
Backpropagation: Errors are propagated backward through the network to update weights and biases. This process is repeated until the model converges to a satisfactory level of accuracy.
Types of Neural Networks
Feedforward Neural Networks (FNN): These networks have connections moving in one direction, from input to output, and are used for tasks like image recognition and natural language processing.
Recurrent Neural Networks (RNN): RNNs have loops in their architecture, allowing them to process sequences of data. They are suitable for tasks like speech recognition and language modeling.
Convolutional Neural Networks (CNN): CNNs are designed for tasks involving grid-like data, such as images and videos. They use convolutional layers to extract features from input data.
7. What is the purpose of cross-validation in machine learning?
Cross-validation is a crucial technique in machine learning that serves a vital purpose - assessing the performance and robustness of a predictive model. Imagine you’re building a machine learning model to predict, let’s say, housing prices. You don’t want your model to be too good at predicting the data it was trained on but terrible at predicting new, unseen data. This is where cross-validation steps in.
Why Cross-Validation Matters
Cross-validation helps us determine how well a model will generalize to unseen data. It’s like a reality check for your machine learning algorithm. Here’s how it works:
You start by splitting your dataset into multiple subsets, often called “folds.” For instance, if you have 1,000 data points and choose 5-fold cross-validation, you’d split your data into five equal parts, each containing 200 data points.
Next, you train your model on four of these folds and use the remaining one for testing. You repeat this process five times, ensuring that each fold takes a turn as the test set. The magic happens when you calculate the performance metrics (like accuracy or mean squared error) for each of these iterations.
The Power of Cross-Validation
The true power of cross-validation lies in its ability to reveal if your model suffers from overfitting or underfitting. Overfitting occurs when your model learns the training data too well, capturing noise and irrelevant patterns. This results in poor performance on new data. On the other hand, underfitting happens when your model is too simplistic and cannot capture the underlying patterns, leading to subpar predictions.
Cross-validation helps you find the sweet spot between these extremes. By evaluating your model’s performance across different subsets of data, you can identify whether it’s learning the essential patterns without getting lost in the noise.
8. What is feature engineering?
Feature engineering is a foundational concept in machine learning, and it’s all about transforming raw data into a format that’s more suitable for predictive modeling. Think of it as sculpting a block of marble into a beautiful statue - you’re chiseling away the unnecessary parts and highlighting the essential features that will help your model make accurate predictions.
Why Feature Engineering Matters
Raw data can be messy and complex. For instance, if you’re working with text data, you might have long paragraphs of text. If you’re dealing with images, you’ll have pixels and colors. Feature engineering involves converting this raw data into numeric features that can be easily understood and processed by machine learning algorithms.
Common Techniques in Feature Engineering
One-Hot Encoding: This technique is used for categorical data. It transforms categories into binary values, making it easier for algorithms to understand.
Scaling and Normalization: Features in your data might have different scales, like age (in years) and income (in thousands of dollars). Scaling and normalization ensure that all features have a similar scale, preventing some features from dominating others.
Feature Extraction: Sometimes, you can create new features from existing ones. For example, if you have a dataset of birthdates, you can extract the year of birth as a separate feature.
Text Vectorization: Converting text data into numerical form is crucial. Techniques like TF-IDF (Term Frequency-Inverse Document Frequency) and Word Embeddings (like Word2Vec) are commonly used for this purpose.
Dimensionality Reduction: When dealing with high-dimensional data, reducing the number of features can be beneficial. Techniques like Principal Component Analysis (PCA) help in capturing the most critical information while reducing dimensionality.
The Art of Feature Engineering
Feature engineering is often considered an art because it requires a deep understanding of both the data and the problem you’re trying to solve. It’s not just about blindly applying techniques but about making informed decisions based on domain knowledge.
In machine learning, the quality of your features can significantly impact the model’s performance. Well-engineered features can turn a mediocre model into a high-performing one. Therefore, feature engineering is a critical step in the machine learning pipeline, where the right transformations can unlock the hidden potential in your data.
9. Explain the bias-variance trade-off.

10. What is regularization in machine learning?
Regularization is a crucial concept in the realm of machine learning. It’s a technique used to prevent overfitting, which occurs when a machine learning model becomes too complex and fits the training data too closely, resulting in poor generalization to new, unseen data.
In simpler terms, regularization is like a control mechanism for machine learning models. It helps strike a balance between fitting the training data perfectly and making sure the model can make accurate predictions on new data.
There are different types of regularization techniques, including L1 regularization, L2 regularization, and dropout. These methods work by adding a penalty term to the model’s loss function, which discourages the model from assigning too much importance to any single feature or parameter. This encourages the model to generalize better.
For example, think of it like learning to play a musical instrument. If you practice a piece of music too much, you might become excellent at playing that specific piece, but you won’t necessarily be good at playing other songs. Regularization ensures that your machine learning model doesn’t become too fixated on the training data, allowing it to perform well on new, unseen data as well.
Become a Blockchain Developer Today!
15 Hours | Self-Paced
Offers Applicable
11. What is the K-nearest neighbors (KNN) algorithm?
The K-nearest neighbors (KNN) algorithm is a fundamental technique in machine learning, especially in the field of supervised learning. It’s a simple yet powerful method used for classification and regression tasks.
In KNN, the “K” represents the number of nearest neighbors the algorithm considers when making a prediction. Here’s how it works: When you want to predict the class or value of a data point, KNN looks at the K data points in the training set that are closest to the point you want to classify. These closest neighbors “vote” on the outcome, and the majority class or average value becomes the prediction for the new data point.
One of the strengths of KNN is its simplicity and ability to handle non-linear data. However, it’s important to choose an appropriate value for K, as too small a value can make the model sensitive to noise, while too large a value may result in overly smoothed predictions.
Imagine KNN as seeking advice from your closest friends. If you want to know about a movie, you might ask your five closest friends for their opinions, and the majority vote determines your decision. KNN operates in a similar way, making predictions based on the consensus of nearby data points.
12. What are hyperparameters in machine learning?
Hyperparameters are vital components in machine learning algorithms. They are settings or configurations that are not learned from the training data but are set prior to training. These parameters control various aspects of the learning process and significantly impact a model’s performance.
Think of hyperparameters as the settings on a musical instrument. Just as adjusting the tension of guitar strings can affect the sound, hyperparameters can influence how a machine learning model behaves.
Common hyperparameters include the learning rate, which determines the step size in the optimization process, and the number of hidden layers and neurons in a neural network. Choosing the right hyperparameters can be a challenging task, and it often involves a process called hyperparameter tuning, where different combinations are tested to find the optimal configuration for a given problem.
13. What is gradient descent?
Gradient descent is a fundamental optimization technique used in the world of artificial intelligence and machine learning. Its primary purpose is to fine-tune the parameters of machine learning models to minimize prediction errors. It operates based on mathematics and plays a vital role in model training.
Imagine you’re on a journey to find the lowest point in a hilly terrain. Your starting position is random, and your objective is to reach the valley’s lowest point-the point of minimal error. Gradient descent serves as your guiding compass in this endeavor.
Here’s a simplified explanation:
Initialization: Start with initial parameter values.
Calculate Gradient: Compute the slope (gradient) of the cost function.
Update Parameters: Adjust parameters in the direction of the gradient.
Iterate: Repeat steps 2 and 3 until convergence.
Minimization: Find parameters that minimize the cost function.
Optimal Model: These parameters represent the optimal model.
Application: Use the model for predictions.
Fine-tuning: Adjust hyperparameters for efficiency.
Variations: Explore different gradient descent variants.
14. Explain the concept of dimensionality reduction.

Dimensionality reduction is a critical concept in the realm of artificial intelligence, particularly when dealing with datasets containing a large number of features or dimensions. It’s all about simplifying complex data while preserving its core information-a vital technique for making data more manageable, interpretable, and suitable for machine learning.
Imagine you have a dataset with numerous features, each representing different aspects of the data. High dimensionality can lead to several challenges, including increased computational complexity and the risk of overfitting, where a model learns noise instead of meaningful patterns. Dimensionality reduction techniques address these issues.
Two common methods for dimensionality reduction are Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE).
15. What is clustering in unsupervised learning?
Clustering is a fundamental technique in unsupervised learning, a branch of artificial intelligence where the primary goal is to discover natural groupings or clusters within a dataset without predefined labels or categories. Think of it as sorting objects into piles based on their similarities, but in a high-dimensional space.
The main objective of clustering is to unveil hidden patterns and structures within data. For instance, if you have a collection of customer data, clustering can help identify groups of customers who exhibit similar behaviors or preferences, even if you don’t know in advance what those groups might be.
One popular clustering algorithm is K-Means. It partitions the data into ‘k’ clusters, where ‘k’ is a user-defined parameter. The algorithm iteratively assigns data points to clusters based on their similarity to the cluster’s center (centroid), aiming to minimize the distance between data points within the same cluster.
Another approach, hierarchical clustering, creates a tree-like structure of clusters, revealing relationships at different levels of granularity. This technique is valuable when you want to explore data at various resolutions.
16. What are the evaluation metrics for classification problems?
In the realm of classification problems, several evaluation metrics help assess the performance of machine learning models. These metrics provide valuable insights into how well a model can distinguish between different classes or categories. Here, we’ll delve into the key evaluation metrics you should know:
Accuracy: Accuracy is a fundamental metric, measuring the proportion of correct predictions out of the total predictions made by the model. It’s a simple and intuitive metric, suitable for balanced datasets. However, in cases of imbalanced datasets, accuracy can be misleading.
Precision: Precision focuses on the accuracy of positive predictions. It calculates the ratio of true positives to the sum of true positives and false positives. Precision is crucial when the cost of false positives is high, such as in medical diagnoses or fraud detection.
Recall (Sensitivity): Recall, also known as sensitivity or true positive rate, assesses the model’s ability to correctly identify all relevant instances of a class. It’s calculated as the ratio of true positives to the sum of true positives and false negatives. High recall is vital in scenarios where missing positive cases is costly.
F1 Score: The F1 score combines precision and recall into a single metric, providing a balanced assessment of a model’s performance. It’s particularly useful when there’s an uneven class distribution. The F1 score is the harmonic mean of precision and recall.
Specificity: Specificity measures the ability of a model to correctly identify negative instances. It’s calculated as the ratio of true negatives to the sum of true negatives and false positives. Specificity is crucial in applications where false alarms for negative cases are undesirable.
17. What is the ROC curve?
The ROC curve is a graphical representation of a classifier’s performance across various thresholds for binary classification problems. It plots the true positive rate (recall) against the false positive rate (1-specificity) at different threshold settings. The curve helps in selecting an optimal threshold that balances sensitivity and specificity.
AUC-ROC (Area Under the ROC Curve): The AUC-ROC score quantifies the overall performance of a binary classification model. It represents the area under the ROC curve. A higher AUC-ROC value indicates better discrimination between positive and negative classes.
18. What is the precision-recall trade-off?
The precision-recall trade-off is a fundamental concept in machine learning, particularly in binary classification. It highlights the inverse relationship between precision and recall. As you increase the threshold for classifying an instance as positive, precision goes up, but recall tends to decrease.
This trade-off is crucial because, in practice, you often need to choose an optimal threshold based on your specific problem’s requirements. For instance, in a medical diagnosis scenario, you might prioritize high recall to ensure all relevant cases are detected, even if it means more false positives (lower precision).
19. What is the difference between batch and online learning?

20. Explain the concept of reinforcement learning.
Reinforcement learning is a fascinating part of AI. It’s like teaching a dog new tricks through rewards and punishments. Here, an agent interacts with an environment, taking actions to maximize a reward. Think of it as a game where the agent learns by trial and error.
It’s widely used in autonomous vehicles and game-playing AI, like AlphaGo. Reinforcement learning algorithms, such as Q-learning and Deep Q Networks (DQN), make it possible for AI to learn complex tasks on its own.
Become a Blockchain Architect Today!
12 Hours | Self-Paced
Offers Applicable
21. What is deep learning?
Deep learning is a subset of machine learning, and it’s inspired by how our brains work. In simple terms, it’s about training artificial neural networks to perform tasks. Imagine a brain with interconnected neurons, but in this case, it’s virtual.
Deep learning powers many AI breakthroughs, from image and speech recognition to natural language processing. It’s behind virtual assistants like Siri and Alexa and even self-driving cars. Deep learning models, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), are used to process data in a hierarchical and sequential manner, enabling AI to understand and make decisions like humans, but at incredible speeds.
22. What is the purpose of activation functions in neural networks?
Activation functions play a pivotal role in the world of neural networks. Imagine them as gatekeepers within each neuron, deciding whether a signal should pass through or not. But why do we need them?
Activation functions serve two primary purposes:
Introducing Non-Linearity: Without activation functions, a neural network would essentially be a linear model. Activation functions inject non-linearity, enabling the network to learn complex patterns and relationships in data. This is crucial because most real-world problems are non-linear in nature.
Signal Normalization: Another vital role of activation functions is to normalize the output of each neuron. They ensure that the values transmitted to the next layer fall within a specific range, typically between 0 and 1 or -1 and 1. This normalization helps in stabilizing the learning process, making it more efficient and preventing numerical instability.
23. What is the vanishing gradient problem?
The vanishing gradient problem is a formidable challenge in deep learning, particularly in training deep neural networks. It occurs during the backpropagation phase, where the network adjusts its weights to minimize errors. But what exactly is this problem?
Imagine a deep neural network with many layers. During backpropagation, gradients (derivatives of the loss with respect to the network’s parameters) are computed and used to update these parameters. The issue arises when these gradients become exceedingly small as they are propagated backward through the network, especially in networks with many layers.
As a result, layers closer to the input receive significant updates, while those further away receive tiny or vanishing updates. This means that neurons in deep layers learn very slowly, if at all, and the network struggles to capture long-range dependencies in the data.
To mitigate the vanishing gradient problem, techniques like using specific activation functions (e.g., ReLU), careful weight initialization, and employing architectures like LSTM or GRU have been developed. These methods enable deep networks to learn more effectively by addressing the gradient vanishing issue.
24. What is transfer learning in deep learning?
Transfer learning is a game-changer in the realm of deep learning. It’s like having a head start in solving new problems using the knowledge gained from solving previous, related tasks. Let’s delve into what transfer learning entails:
Transfer learning involves taking a pre-trained neural network (often trained on a massive dataset) and fine-tuning it for a different but related task. Instead of starting from scratch, the network already possesses knowledge about features and patterns that are generally applicable, like detecting edges or basic shapes.
Here’s how transfer learning works:
Pre-trained Models: Researchers and data scientists train complex neural networks on extensive datasets for various tasks, such as image recognition or natural language understanding.
Fine-tuning: You take one of these pre-trained models and modify its final layers to adapt it to your specific task. These modified layers learn task-specific information, while the earlier layers retain their general knowledge.
Efficient Learning: Thanks to the initial training, the model starts with a solid foundation, which allows it to learn your new task with far less data and computation compared to training from scratch.
25. What is natural language processing (NLP)?
Natural Language Processing, or NLP for short, is a field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language in a valuable way. It’s like teaching machines to comprehend and communicate with us in a manner that feels almost human.
NLP plays a pivotal role in a wide range of applications, from chatbots and virtual assistants to sentiment analysis and language translation. Its significance lies in the fact that most of the data generated and consumed by humans is in the form of text or speech, making NLP essential in harnessing the power of this data.
26. What are some common algorithms used in NLP?
In the realm of NLP, several algorithms and techniques are used to process and understand natural language. These algorithms act as the building blocks for various applications. Here are some of the most common ones:
Tokenization: This involves breaking down a text into smaller units, such as words or phrases, for easier analysis.
Stemming and Lemmatization: These techniques reduce words to their root forms to handle variations (e.g., “running” to “run”).
Named Entity Recognition (NER): It identifies entities like names, dates, and locations within text.
Part-of-Speech Tagging (POS): It assigns grammatical labels to words (e.g., noun, verb) for deeper analysis.
Sentiment Analysis: This assesses the emotional tone of text, useful in understanding customer feedback and opinions.
Machine Translation: Algorithms like the Transformer model underlie translation services like Google Translate.
Topic Modeling: Techniques like Latent Dirichlet Allocation (LDA) help uncover the underlying themes in a body of text.
Word2Vec and GloVe: These are word embedding techniques, which we’ll discuss next.
27. Explain the concept of word embeddings.
Word embeddings are a fascinating aspect of NLP. They represent words or phrases as dense vectors in a multi-dimensional space, where the position of a word vector encodes its semantic meaning. This concept revolutionized how computers understand language.
For instance, in traditional text analysis, words were treated as discrete symbols. But with word embeddings, words with similar meanings are closer in this vector space. This allows NLP models to grasp context and relationships between words.
Word2Vec and GloVe are popular word embedding models. They learn these vector representations by analyzing large datasets of text, capturing the meaning and context of words based on their co-occurrence patterns. This enables algorithms to perform tasks like word similarity, document classification, and sentiment analysis more effectively.
28. What is a recommendation system in machine learning?
In the world of machine learning, recommendation systems play a pivotal role. These systems are the driving force behind personalized recommendations you receive on platforms like Amazon, Netflix, or Spotify. But what exactly is a recommendation system?
At its core, a recommendation system, often referred to as a recommender system, is a type of software application that provides personalized suggestions to users. These suggestions could be anything from product recommendations to movie choices or even music playlists. The ultimate goal is to enhance user experience by delivering content that aligns with their preferences and interests.
To achieve this, recommendation systems rely on various algorithms and data analysis techniques. They consider your past interactions, such as the products you’ve bought, the movies you’ve watched, or the songs you’ve listened to. By analyzing this data, these systems identify patterns and trends in your behavior. They then use this information to make predictions about what you might like in the future.
There are primarily three types of recommendation systems:
Collaborative Filtering: This method looks at the behavior and preferences of users who are similar to you. It suggests items that people with similar tastes have liked. Collaborative filtering can be user-based or item-based, depending on whether it focuses on similarities between users or items.
Content-Based Filtering: Content-based recommendation systems consider the attributes of the items you’ve interacted with and suggest similar items based on those attributes. For example, if you’ve watched science fiction movies, it will recommend more sci-fi films.
Hybrid Systems: These systems combine both collaborative and content-based approaches to provide more accurate and diverse recommendations.
In summary, recommendation systems in machine learning are the engines that power personalized suggestions, making our online experiences more engaging and tailored to our preferences.
29. What is ensemble learning?
Ensemble learning is a powerful technique in machine learning that involves combining multiple models to improve predictive performance. Think of it as the “strength in numbers” approach. Instead of relying on a single model, ensemble learning leverages the diversity of several models to make better predictions.
Here’s how it works:
Ensemble learning typically involves two main components:
Base Models: These are individual machine learning models, each trained on different subsets of the data or using different algorithms. They can be decision trees, support vector machines, neural networks, or any other model suitable for the task at hand.
Aggregation: The predictions from these base models are combined or aggregated to make a final prediction. The way this aggregation is done depends on the specific ensemble technique being used.
There are several popular ensemble techniques, including:
Bagging (Bootstrap Aggregating): In bagging, multiple base models are trained independently on random subsets of the training data, and their predictions are averaged or voted upon to make a final prediction. Random Forest is a famous example of a bagging ensemble.
Boosting: Boosting focuses on training base models sequentially, where each subsequent model corrects the errors of the previous one. Gradient Boosting and AdaBoost are well-known boosting algorithms.
Stacking: Stacking involves training multiple base models and then training a meta-model that learns how to best combine their predictions. It’s like having a “supermodel” that takes advice from others.
Ensemble learning is a game-changer because it often leads to better generalization, increased accuracy, and reduced overfitting compared to using a single model. It’s a valuable tool in a machine learning practitioner’s toolkit, helping to tackle complex problems and improve predictive outcomes.
30. Can you explain bias and fairness in machine learning models?
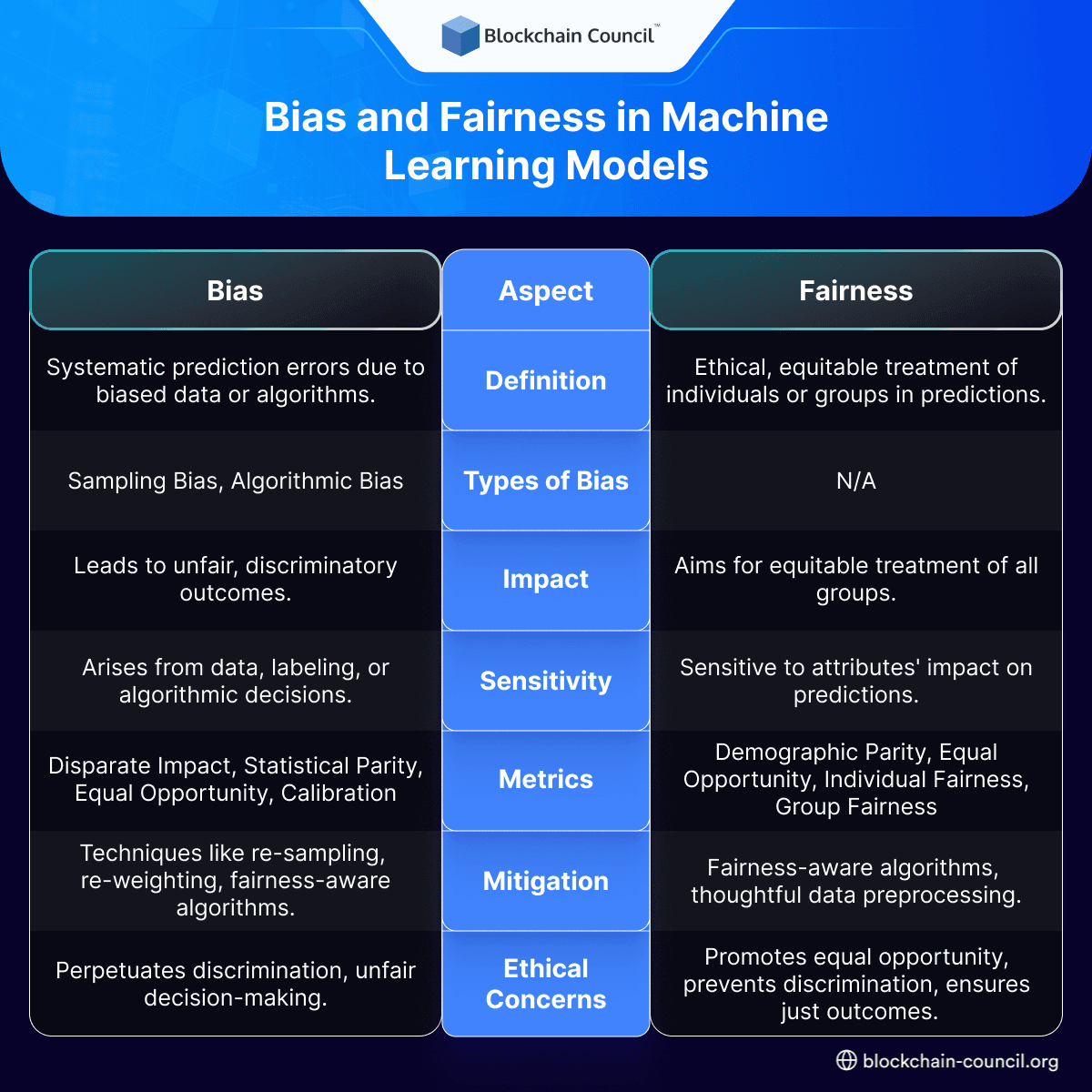
Conclusion
As we wrap up this journey through the top 30 machine learning interview questions and answers, it’s clear that the world of machine learning is as fascinating as it is rewarding. Looking ahead, the demand for AI and Machine Learning Specialists is set to soar, with an expected 40% growth, equivalent to 1 million jobs, as AI and machine learning continue to transform industries.
Remember, the field of machine learning is ever-evolving, and staying updated with the latest trends and technologies is essential. Your journey in machine learning is not just about interviews; it’s about contributing to the exciting advancements in this field.
Frequently Asked Questions
What is Machine Learning?
Machine Learning is a subset of artificial intelligence that focuses on developing algorithms and models.
The models enable computers to learn from and make predictions or decisions based on data.
What are the types of Machine Learning?
There are three main types of Machine Learning:
Supervised Learning: It involves training a model on labeled data to make predictions.
Unsupervised Learning: It deals with finding patterns or structures in unlabeled data.
Reinforcement Learning: It is about training agents to make decisions by interacting with an environment.
What is Overfitting in Machine Learning?
Overfitting occurs when a machine learning model performs well on the training data but poorly on unseen data.
It happens when the model is too complex and captures noise in the training data.
What is a Neural Network?
A neural network is a computational model inspired by the human brain.
It consists of interconnected nodes (neurons) organized in layers to process and analyze data, commonly used for tasks like image recognition and natural language processing.
How do you handle missing data in a dataset?
There are several approaches to handle missing data:
Removing rows or columns with missing values (if the data loss is acceptable).
Imputing missing values with statistical measures like mean, median, or mode.
Using advanced techniques like regression or machine learning to predict missing values based on other features.
Related Articles
View All
AI & ML
Forward Deployed Engineer Interview Questions and Preparation Guide for 2026
Prepare for Forward Deployed Engineer interview questions in 2026 with coding, system design, customer case, AI, data, security, and Web3 guidance.

AI & ML
Meta AI Career Opportunities: Skills for Generative AI and Machine Learning Roles
Explore Meta AI career opportunities, required generative AI and machine learning skills, salary ranges, role types, and a practical learning path.

AI & ML
Top GPT 5.6 Use Cases in Blockchain, Web3, Cybersecurity, and Business
Explore GPT 5.6 use cases across blockchain, Web3, cybersecurity, and business, with practical workflows, risks, and certification paths.
Trending Articles
The Role of Blockchain in Ethical AI Development
How blockchain technology is being used to promote transparency and accountability in artificial intelligence systems.
AWS Career Roadmap
A step-by-step guide to building a successful career in Amazon Web Services cloud computing.
What is AWS? A Beginner's Guide to Cloud Computing
Everything you need to know about Amazon Web Services, cloud computing fundamentals, and career opportunities.