Natural Language Processing (NLP)

Introduction to Natural Language Processing (NLP)
In the world of artificial intelligence and language processing, Natural Language Processing (NLP) stands out as a revolutionary field that seeks to bridge the gap between human communication and computational systems. NLP has gained immense popularity and practical applications in recent years, transforming the way we interact with technology and opening up new possibilities across various industries.
This article serves as a comprehensive guide to NLP, providing an overview of its fundamental concepts, techniques, and applications. Whether you are a seasoned AI enthusiast or someone curious about the fascinating world of NLP, this guide will equip you with the knowledge necessary to navigate and appreciate the power of Natural Language Processing.

Definition of Natural Language Processing (NLP)
Natural Language Processing (NLP) is a multidisciplinary field of study that combines linguistics, computer science, and artificial intelligence to enable computers to understand and interact with human language in a meaningful way. It focuses on bridging the gap between human language and machine understanding, facilitating tasks such as text analysis, sentiment analysis, language translation, and even conversational agents like chatbots and virtual assistants.
NLP employs a variety of techniques, including statistical models, machine learning algorithms, and deep neural networks, to process, analyze, and generate human language. These techniques enable machines to extract information, recognize patterns, and derive meaning from unstructured textual data, fostering a deeper understanding of human communication.
Key Challenges in NLP
While NLP has made significant advancements, several challenges persist in this field:

Overcoming these challenges requires continuous research, innovation, and the application of robust algorithms that can adapt to the complexities of human language.
NLP Applications and Use Cases
The realm of NLP extends far beyond theoretical concepts, with a multitude of practical applications and use cases across diverse industries:
- Sentiment Analysis: NLP analyzes feedback, reviews, and social media to gauge public sentiment. Guides decision-making and customer-centric strategies.
- Information Extraction: NLP extracts structured information from unstructured data. Automates data processing, accelerates research, improves retrieval.
- Machine Translation: NLP revolutionizes language translation. Breaks barriers, enables global communication and cultural exchange.
- Chatbots & Virtual Assistants: NLP powers conversational interfaces. Provides automated support, personalized recommendations, streamlines tasks.
- Text Summarization: NLP condenses texts into concise summaries. Saves time, provides quick access to relevant information.
- Voice Recognition: NLP transforms spoken language to written text. Used in transcription, voice assistants, accessibility tools.
These are just a few examples of the vast range of applications NLP offers. From healthcare and finance to marketing and education, NLP is revolutionizing industries and enhancing human-machine interactions
Linguistic Foundations for NLP
Syntax and Parsing in NLP
Syntax and parsing play a pivotal role in extracting meaningful information from text. Syntax deals with the arrangement of words and their relationships in a sentence, while parsing involves breaking down sentences into constituent parts for deeper analysis. By utilizing techniques such as dependency parsing and constituency parsing, NLP models can comprehend sentence structure, identify subjects, objects, and modifiers, and derive syntactic patterns that aid in language understanding and generation.
Morphology and Lemmatization
Morphology delves into the study of word forms and their internal structure. By analyzing prefixes, suffixes, and roots, NLP models gain insights into word variations and inflections.

In the table above, we observe different morphological variations and their corresponding lemmatized forms. For instance, the word “cats” is lemmatized to its base form “cat,” while “running” becomes “run.” Similarly, “happier” is transformed into “happy,” “dogs” becomes “dog,” “swam” becomes “swim,” and “friendliest” is lemmatized to “friendly.”
Lemmatization aids NLP algorithms in reducing word variations and enhancing language understanding. By reducing words to their base forms, NLP models can recognize the semantic similarities between related words and avoid redundancy in language processing tasks. Lemmatization also simplifies information retrieval, entity recognition, and semantic analysis by grouping words with similar meanings together.
Through effective morphological analysis and lemmatization, NLP systems can handle different word forms, resolve ambiguity, and improve accuracy in various language processing tasks such as text classification, information retrieval, and sentiment analysis.
Semantics and Word Sense Disambiguation
Semantics explores the meaning of words, phrases, and sentences, enabling NLP models to comprehend context and infer intent. Word Sense Disambiguation (WSD) plays a vital role in resolving ambiguity by determining the correct sense of a word within a given context. By leveraging linguistic resources, knowledge graphs, and context clues, NLP models can accurately decipher word meanings and enable more precise language understanding, machine translation, and information retrieval.
Pragmatics and Discourse Analysis
Pragmatics focuses on the study of language in use, considering context, speaker intentions, and implied meaning. Discourse analysis further investigates the structure and coherence of larger units of text, such as paragraphs or entire documents. By incorporating pragmatic and discourse analysis techniques, NLP systems can grasp implied meanings, detect sentiment, identify rhetorical devices, and build conversational agents capable of engaging in natural and meaningful dialogue.
Text Preprocessing for NLP
Text Normalization Techniques
In natural language processing (NLP), text normalization refers to the process of transforming text into a standard and consistent format. It involves techniques such as:

By normalizing the text, we can create a clean and uniform representation that enhances the accuracy and efficiency of subsequent NLP tasks.
Tokenization and Sentence Segmentation
Tokenization involves breaking down a text into individual tokens or words, which are the basic units of NLP analysis. It helps in converting unstructured text into structured data that machines can process. Tokenization techniques include:
- Word tokenization: Splitting text into individual words. For example, the sentence “I love natural language processing” would be tokenized into [“I”, “love”, “natural”, “language”, “processing”].
- Sentence segmentation: Dividing text into separate sentences. This is crucial for tasks such as sentiment analysis or machine translation. For instance, the paragraph “NLP is fascinating. It has revolutionized various industries” would be segmented into [“NLP is fascinating.”, “It has revolutionized various industries.”].
Accurate tokenization and sentence segmentation enable efficient analysis and understanding of textual data in NLP applications.
Stop Word Removal and Stemming
Stop words are common words that do not carry significant semantic meaning, such as “the,” “and,” or “in.” Removing these stop words can improve the efficiency of NLP algorithms by reducing noise and focusing on more important words. For example, in the sentence “The cat is sitting on the mat,” removing the stop word “the” would result in “cat sitting on mat.”
Stemming is the process of reducing words to their root or base form. It involves removing suffixes and prefixes to capture the core meaning of a word. For instance, stemming would convert “running,” “ran,” and “runs” to their common base form “run.”
By removing stop words and applying stemming techniques, we can enhance the performance of NLP models and improve the accuracy of downstream tasks such as text classification or information retrieval.
Handling Special Characters and Symbols
Special characters and symbols, such as hashtags, mentions, or emoticons, are prevalent in social media and online content. They can pose challenges in NLP analysis as they may carry contextual information or convey sentiment. Techniques to handle special characters include:
- Retaining relevant symbols: In some cases, special characters like hashtags (#NLP) or mentions (@user) may contain valuable information. They can be preserved for analysis or used to extract specific features.
- Removing irrelevant symbols: Symbols like punctuation marks, emojis, or HTML tags are often noise in NLP tasks. Removing them can simplify the text and improve the accuracy of subsequent analysis.
- Encoding special characters: In cases where special characters represent specific entities or concepts, encoding them into standardized representations can facilitate further NLP processing.
Proper handling of special characters and symbols ensures that NLP models capture the intended meaning of the text and effectively analyze contextual information.
Statistical Methods in NLP
Language Models and N-grams
Language models serve as the foundation of NLP, facilitating tasks such as machine translation, speech recognition, and text generation. They capture the probability distribution of words or sequences of words in a language. One popular approach is using n-grams, which are contiguous sequences of n words.
For instance, consider the sentence: “The cat sat on the mat.” A unigram language model would focus on individual words, such as “the,” “cat,” “sat,” “on,” and “the.” Meanwhile, a bigram model would analyze pairs of consecutive words like “the cat,” “cat sat,” “sat on,” and “on the.” Higher order n-grams can also be used to capture longer dependencies.
By analyzing the frequencies and co-occurrences of n-grams in a large corpus, language models can predict the likelihood of a given sequence of words. These models are vital in applications like autocomplete suggestions and next word prediction.
Hidden Markov Models (HMM)
Hidden Markov Models (HMMs) are widely used for sequence labeling tasks in NLP. They model a sequence of observable events (words or tags) based on an underlying sequence of hidden states. HMMs assume a Markov property, where the current state depends only on the previous state.
For example, in part-of-speech tagging, HMMs can determine the most likely sequence of tags (e.g., noun, verb, adjective) for a given sentence. The observable events are the words themselves, while the hidden states represent the corresponding parts of speech.
HMMs leverage the Viterbi algorithm to efficiently compute the most probable sequence of hidden states, given the observed sequence. These models have found applications in speech recognition, named entity recognition, and sentiment analysis.
Maximum Entropy Markov Models (MEMM)
Maximum Entropy Markov Models (MEMMs) build upon the framework of HMMs but introduce more flexibility in incorporating features. MEMMs consider a wider range of contextual information to make predictions, enabling better performance in various NLP tasks.
Unlike HMMs, which assume independence between features, MEMMs utilize a maximum entropy principle to estimate the probability distribution of the next state given the current state and observed features. This allows for the inclusion of rich contextual information, such as neighboring words and their features.
MEMMs have been successful in tasks like named entity recognition, part-of-speech tagging, and information extraction. Their ability to handle complex feature interactions contributes to improved accuracy and performance.
Conditional Random Fields (CRF)
Conditional Random Fields (CRFs) are discriminative models widely employed for sequence labeling tasks. Similar to HMMs and MEMMs, CRFs also infer the most likely sequence of labels given a sequence of observations. However, CRFs directly model the conditional probability distribution without making strong assumptions about independence.
CRFs incorporate a wider range of features, such as lexical, syntactic, and semantic information, to capture complex relationships among the observed variables. They excel in tasks like named entity recognition, part-of-speech tagging, and chunking, where labeling decisions depend on the entire input sequence.
With their ability to handle overlapping features and capture global dependencies, CRFs have become a popular choice in various NLP applications.
Rule-based Methods in NLP

Sentiment Analysis and Opinion Mining

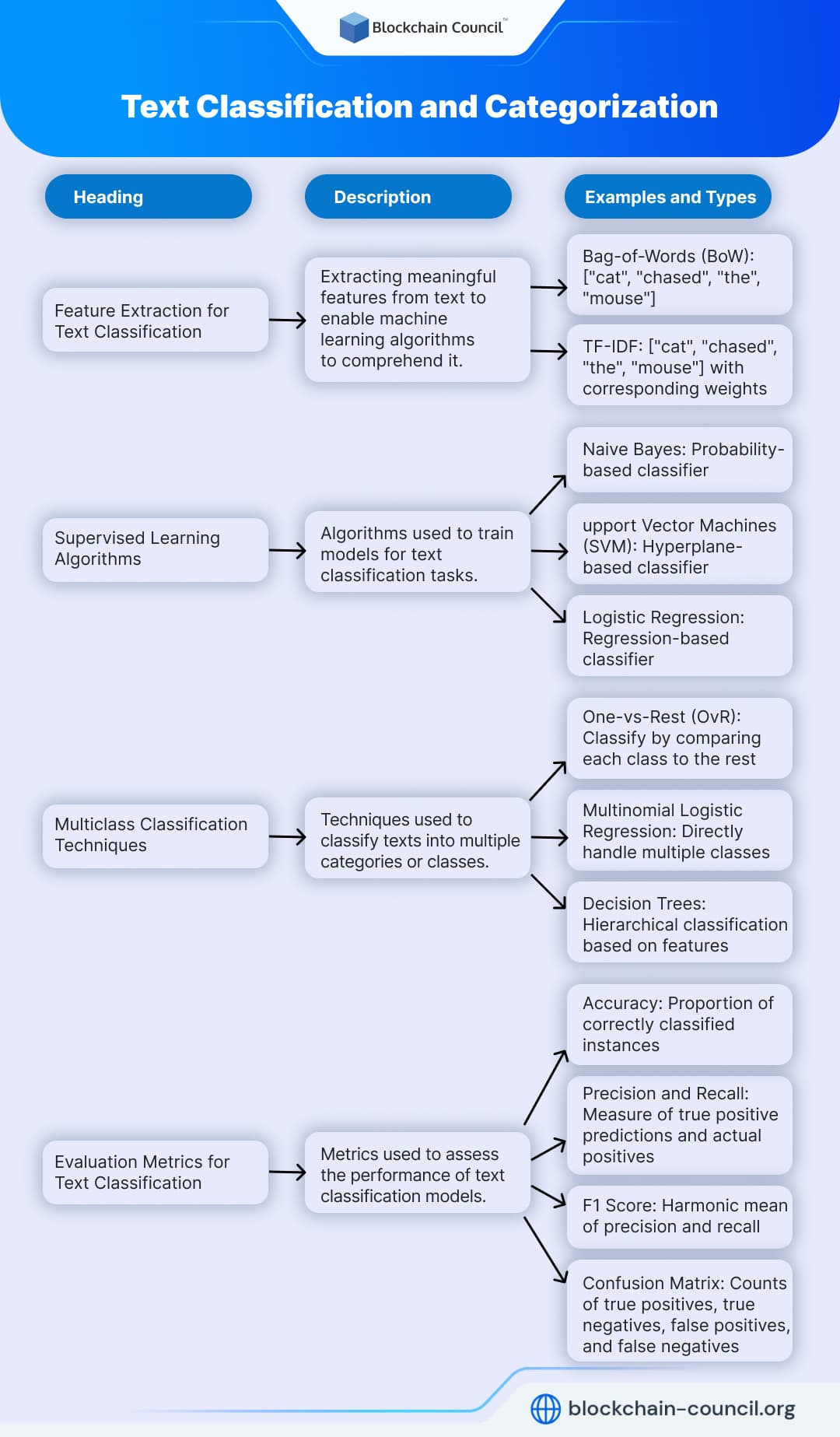
Text Classification and Categorization
Named Entity Recognition (NER)
NER can be approached using different techniques, each with its strengths and weaknesses. Let’s take a closer look at the three main techniques employed in NER:
Rule-based Techniques
Rule-based approaches leverage handcrafted patterns and linguistic rules to identify named entities. These patterns can be based on capitalization, part-of-speech tags, and syntactic dependencies. While rule-based systems can be effective for specific domains or languages with consistent patterns, they often lack generalizability and struggle with handling diverse and noisy text.
Example:
In the sentence “Apple Inc. is headquartered in Cupertino, California,” a rule-based system can identify “Apple Inc.” as an organization based on the capitalized words and the presence of “Inc.”
Statistical Techniques
Statistical approaches utilize machine learning algorithms to automatically learn patterns and features from annotated data. Techniques like Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs) have been widely employed for NER. These models capture contextual information and dependencies between words, making them suitable for capturing complex patterns in text.
Example:
Using a statistical model trained on annotated data, the sentence “I live in New York City” can identify “New York City” as a location entity based on the learned patterns and context
Deep Learning-based Techniques
Deep learning-based approaches, particularly Recurrent Neural Networks (RNNs) and Transformer models, have revolutionized NER by effectively capturing the contextual and semantic information present in text. These models can automatically learn representations and extract features from large-scale data, enabling them to handle complex and varied text sources.
Example:
A deep learning-based NER model can accurately recognize “Barack Obama” as a person entity in the sentence “Former President Barack Obama delivered a speech yesterday.”
Named Entity Recognition in Noisy Text
One of the major challenges in NER is dealing with noisy and unstructured text. Real-world text often contains misspellings, grammatical errors, abbreviations, and informal language. Here are some strategies to address these challenges:
Preprocessing
Text preprocessing techniques such as spell correction, abbreviation expansion, and normalization can be applied to clean noisy text before performing NER. This helps ensure accurate identification and classification of named entities.
Contextual Embeddings
Utilizing pre-trained contextual word embeddings, such as word2vec or GloVe, can enhance the performance of NER models in noisy text. These embeddings capture semantic and syntactic information, aiding in disambiguating entities even in challenging contexts.
Named Entity Linking and Coreference Resolution
Named Entity Linking (NEL) and Coreference Resolution are important steps in NER that aim to connect entities across different mentions and link them to relevant knowledge bases. NEL maps named entities to unique identifiers, while Coreference Resolution resolves references to the same entity across a document.
Evaluation Methods for NER Systems
To assess the performance of NER systems, various evaluation metrics are employed. The commonly used metrics include Precision, Recall, and F1-score. Precision measures the ratio of correctly identified named entities to the total number of predicted entities, while Recall quantifies the ratio of correctly identified entities to the total number of actual entities. F1-score combines both precision and recall into a single measure to evaluate overall performance.
Topic Modeling
Latent Dirichlet Allocation (LDA) Algorithm
At the heart of topic modeling lies the Latent Dirichlet Allocation (LDA) algorithm. LDA is a probabilistic model that uncovers latent topics within a corpus by assigning words to these topics based on their statistical distributions. Think of it as a recipe for discovering the underlying themes in a text.
To illustrate its power, let’s consider an example. Suppose we have a collection of articles about movies. LDA can help identify topics such as “action films,” “romantic comedies,” and “documentaries” by analyzing the words present in the articles and their relationships. Each topic comprises a distribution of words, enabling us to understand the main ideas prevalent in the corpus.
Non-negative Matrix Factorization (NMF) for Topic Modeling
Another approach to topic modeling is Non-negative Matrix Factorization (NMF). Unlike LDA, which relies on probabilistic modeling, NMF is a linear algebra-based technique that decomposes a matrix into non-negative factors, representing topics and their associated word distributions.
Let’s delve deeper into this concept with an example. Imagine we have a dataset of customer reviews about electronic products. By applying NMF, we can extract topics such as “product performance,” “user experience,” and “customer support.” This approach provides a different perspective on topic modeling and can be particularly useful when dealing with non-probabilistic data.
Evaluation and Interpretation of Topic Models
Once we’ve generated topic models, the next step is to evaluate and interpret them. Evaluation metrics help us assess the quality of our models and compare their performance. Two commonly used metrics are coherence and perplexity.
Coherence measures the semantic similarity of words within a topic, indicating how well the topic captures a specific concept. Perplexity, on the other hand, quantifies how well a topic model predicts unseen data. These metrics aid in selecting the optimal number of topics and refining the model for better results.
Interpreting topic models involves understanding the significance of each topic and assigning human-readable labels to them. This step requires domain expertise and careful analysis of the most representative words in each topic. Visualization techniques, such as word clouds, bar charts, and network graphs, facilitate the interpretation process.
Also Read: Master the Art of AI
Dynamic Topic Modeling and Topic Evolution Analysis
The world is ever-changing, and so are the topics discussed in textual data. To capture the dynamic nature of topics over time, dynamic topic modeling techniques come into play. These methods allow us to identify topic shifts, emerging trends, and topic evolution patterns.
Topic Evolution Over Time
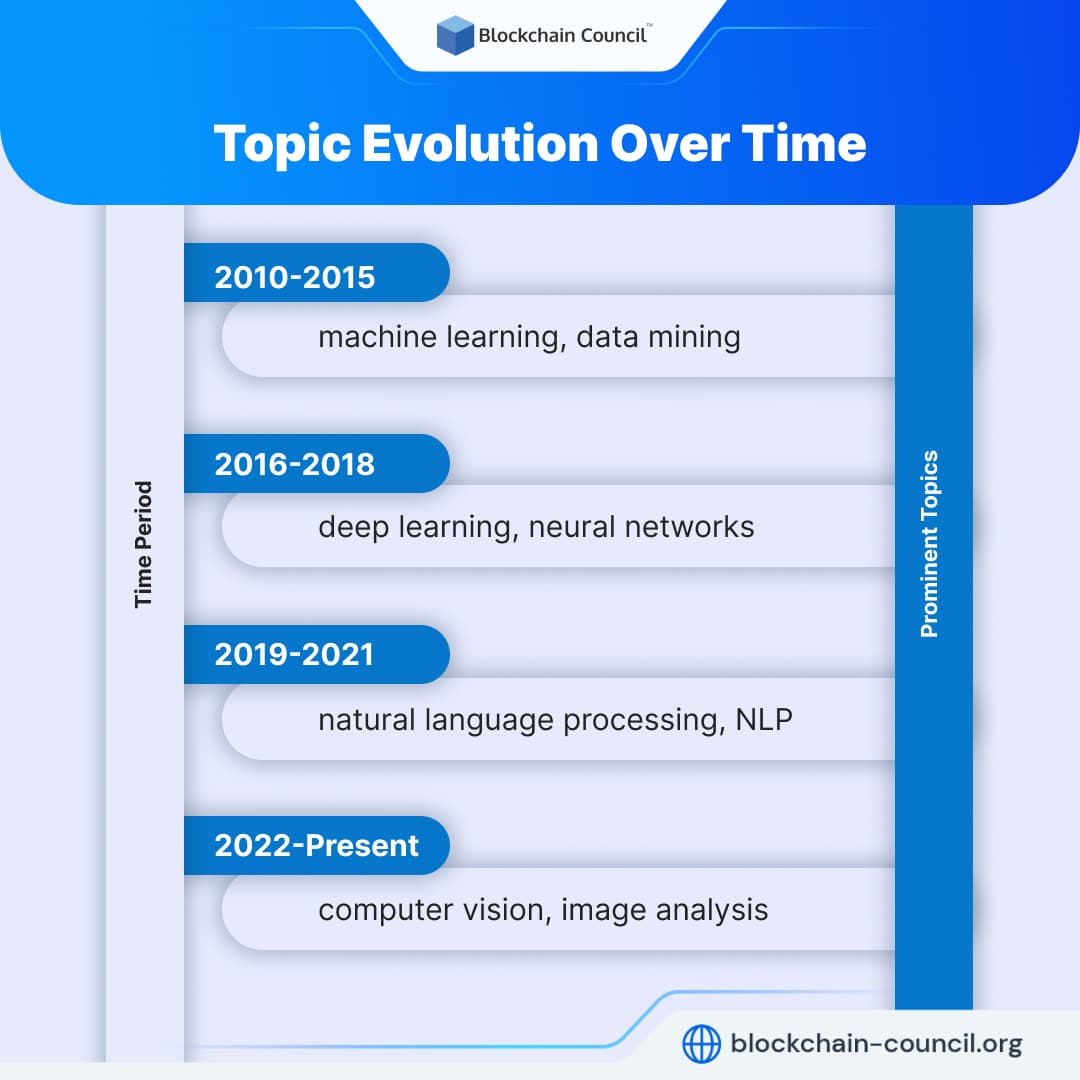
By analyzing temporal data, we can observe how topics gain or lose prominence, how their associations change, and how new topics emerge. For instance, in social media analysis, dynamic topic modeling can help us track the evolution of discussions surrounding a particular event or identify emerging themes within a given timeframe.
Word Embeddings and Word Vectorization
Word2Vec and Skip-gram Models
Word2Vec is a popular model for word embeddings that leverages neural networks to generate high-dimensional representations of words. It consists of two primary approaches: Continuous Bag of Words (CBOW) and Skip-gram. Let’s focus on the Skip-gram model.
The Skip-gram model aims to predict the context words given a target word. It learns by maximizing the probability of predicting the surrounding words using the target word. By iteratively training on a large corpus, Skip-gram generates word vectors that capture semantic relationships between words. For instance, it can identify that “king” is to “queen” as “man” is to “woman.”
GloVe: Global Vectors for Word Representation
GloVe, short for Global Vectors for Word Representation, is another powerful word embedding model. It combines the advantages of both global matrix factorization and local context window methods. GloVe constructs a co-occurrence matrix to capture the statistical relationships between words. By factorizing this matrix, it generates word vectors that capture both global and local context information. This results in embeddings that exhibit excellent performance on various NLP tasks.
Evaluation of Word Embeddings
To assess the quality and effectiveness of word embeddings, several evaluation techniques are employed. Two commonly used evaluation methods include word similarity and analogy tasks.
Word similarity tasks measure the similarity between word pairs using predefined human judgments. For example, given the word pair “cat” and “kitten,” the word similarity task aims to determine the similarity score based on their semantic relationship.
Analogy tasks, on the other hand, evaluate the ability of word embeddings to reason and complete analogical relationships. For instance, if we have the analogy “man:woman :: king:?”, the model should be able to infer the correct missing word “queen” based on the learned word embeddings.
Contextualized Word Embeddings
While traditional word embeddings provide static representations of words, contextualized word embeddings take into account the surrounding context, leading to more nuanced and dynamic representations. Let’s explore some prominent models in this category:

Text Generation with Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNN) Architecture
Recurrent Neural Networks (RNNs) are designed to effectively handle sequential data by introducing loops within the network architecture. Unlike feedforward neural networks, RNNs have connections that allow information to flow not only from input to output but also from one step to the next within the sequence. This makes RNNs suitable for tasks that involve a temporal component, such as text generation, speech recognition, and translation.
The key feature of an RNN is its ability to maintain a hidden state, which captures the context from previous inputs. This hidden state is updated at each time step and serves as a memory mechanism for the network. By incorporating this recurrent connection, RNNs can capture long-term dependencies and generate text that exhibits coherent and contextualized information.
LSTM and GRU Cells for Sequence Modeling

Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) are two variants of RNN cells that have proven to be highly effective in sequence modeling tasks.
LSTM introduces memory gates that control the flow of information, allowing the network to selectively remember or forget certain elements. These gates, namely the input gate, forget gate, and output gate, regulate the flow of information in and out of the LSTM cell, providing it with the ability to capture long-term dependencies while mitigating the vanishing gradient problem.
GRU, on the other hand, simplifies the LSTM architecture by combining the forget and input gates into a single update gate. This reduces the number of parameters and computational complexity, making it more computationally efficient while still achieving impressive performance in sequence modeling tasks.
Text Generation using Language Models
Language models are at the heart of text generation with RNNs. These models learn the statistical properties of the input text and use that knowledge to generate new sequences of text. A popular approach is to train a language model using a large corpus of text data and then use it to generate text based on a given prompt or seed.
During text generation, the language model takes the seed input and predicts the most probable next word or character based on the learned statistical patterns. This predicted word is then appended to the seed, creating a new input sequence. By iteratively repeating this process, the model generates text that resembles the patterns observed in the training data.
Also read: What is Generative Artificial Intelligence
Evaluating and Controlling Text Generation Quality
Evaluating the quality of generated text is a crucial aspect of text generation with RNNs. Several metrics and techniques can be employed to assess the generated output:
- Perplexity: Perplexity measures how well a language model predicts a given sequence of words. Lower perplexity indicates better performance.
- Human Evaluation: Gathering feedback from human evaluators helps assess the fluency, coherence, and relevance of the generated text.
- Controlling Text Generation: Techniques like temperature scaling and nucleus sampling can be used to control the randomness and diversity of generated text. Higher temperature values increase randomness, while nucleus sampling selects from a subset of the most likely words, ensuring more controlled output.
Machine Translation and Language Generation
Statistical Machine Translation (SMT) Models
Statistical Machine Translation (SMT) models have been the cornerstone of machine translation for decades. SMT relies on statistical models that learn translation patterns from large parallel corpora. These models assign probabilities to different translations based on their occurrence in the training data. One popular algorithm used in SMT is the IBM Model 1, which estimates word-to-word translation probabilities.
Example:
Consider the English sentence “The cat is sitting on the mat” and its translation into French, “Le chat est assis sur le tapis.” SMT models analyze vast bilingual corpora to identify patterns and establish the likelihood of different translations.
Neural Machine Translation (NMT) using Sequence-to-Sequence Models
Neural Machine Translation (NMT) has revolutionized the field of machine translation by employing deep learning techniques. NMT uses neural networks to directly translate text from one language to another, eliminating the need for explicit alignment and word-to-word translation probabilities. Sequence-to-sequence models, consisting of an encoder and a decoder, form the foundation of NMT systems.
Example:
In an NMT system, the encoder processes the input sequence, such as the English sentence “The cat is sitting on the mat,” and converts it into a continuous representation called a “thought vector.” The decoder then generates the corresponding translation, such as the French sentence “Le chat est assis sur le tapis,” based on the thought vector.
Attention Mechanisms in NMT
Attention mechanisms have enhanced the performance of NMT models by enabling them to focus on relevant parts of the input sequence during translation. With attention mechanisms, the decoder can assign different weights to different parts of the source sentence, allowing the model to attend to the most important information while generating translations.
Example:
Using attention mechanisms, an NMT model can give more weight to the word “cat” when translating the sentence “The cat is sitting on the mat,” thereby improving the accuracy and fluency of the translation.
Language generation with transformers: GPT, T5, XLNet

Question Answering Systems
Overview of Question Answering (QA) Systems
QA systems are designed to process natural language questions and provide accurate answers by leveraging the power of NLP techniques. These systems bridge the gap between users and vast repositories of information, facilitating efficient knowledge extraction. QA systems are built upon a foundation of powerful algorithms that analyze and interpret text, enabling them to comprehend queries and retrieve relevant information from various sources
Information Retrieval-based QA Systems
Information Retrieval-based QA systems rely on retrieving relevant documents from a vast collection and extracting answers from them. These systems typically use indexing and search techniques to retrieve documents based on keyword matching and rank them according to relevance. For instance, the popular search engine Google employs an Information Retrieval-based approach to provide answers to user queries.
Reading Comprehension-based QA Systems
Reading Comprehension-based QA systems take a step further by comprehending the context of a given document to generate accurate answers. These systems leverage machine learning algorithms to train on large datasets, enabling them to understand the nuances of language and effectively interpret textual information. An example of a reading comprehension-based system is the Stanford Question Answering Dataset (SQuAD), which focuses on answering questions based on specific passages.
Transformer-based QA Models: BERT, RoBERTa
Transformer-based QA models, such as BERT (Bidirectional Encoder Representations from Transformers) and RoBERTa (Robustly Optimized BERT Approach), have marked a significant advancement in the field of QA systems. These models utilize self-attention mechanisms to capture the dependencies between words in a sentence, enabling them to understand the context and generate more accurate answers.
Comparison of Transformer-based QA Models

Natural Language Understanding (NLU)
Intent Recognition and Slot Filling
Intent recognition is a fundamental aspect of NLU that involves identifying the underlying purpose or intention behind a user’s input. By discerning the user’s intent, NLU systems can deliver contextually relevant responses. Slot filling complements intent recognition by extracting specific pieces of information, known as slots, from user utterances. These slots provide crucial details necessary to fulfill the user’s intent. Together, intent recognition and slot filling form the backbone of effective human-computer interactions.
| User Input | Intent | Slots Extracted |
|---|---|---|
| “Find me a four-star hotel in New York City for two nights.” | Hotel Search | Location: New York CityDuration: Two nightsStar rating: Four stars |
Dialogue State Tracking
Dialogue state tracking involves maintaining an understanding of the ongoing conversation by tracking the state of the dialogue. It allows NLU systems to keep a contextual understanding of the user’s previous queries and responses, ensuring a coherent and personalized conversation. By continuously updating the dialogue state, NLU systems can provide more accurate and relevant information to users.
Dialogue State Tracking Example
| User Input | Dialogue State |
|---|---|
| “What is the status of my order?” | Previous inquiry: Order StatusCurrent dialogue state: Order Status |
| “Can I change the shipping address?” | Previous inquiry: Order StatusCurrent dialogue state: Shipping Address |
Semantic Parsing and Logical Form Generation
Semantic parsing involves converting natural language expressions into structured representations that machines can understand. It enables the extraction of underlying meaning from textual input, paving the way for further analysis and processing. Logical form generation focuses on transforming these structured representations into executable actions or queries, facilitating accurate and precise responses.
Semantic Parsing and Logical Form Generation Example
| User Input | Intent | Slots Extracted |
|---|---|---|
| “What is the weather forecast for tomorrow in San Francisco?” | Weather Forecast | Location: San Francisco, Date: Tomorrow |
Language Understanding with Pre-trained Models:
Pre-trained models have revolutionized the field of NLU by leveraging vast amounts of text data to develop language understanding capabilities. These models, such as BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and RoBERTa (Robustly Optimized BERT Approach), are trained on large-scale datasets and encode contextual information into word representations.
Pre-trained Model Examples
| Pre-trained Model | Description |
|---|---|
| BERT | Bidirectional model that captures contextual relationships between words and produces contextualized word representations. |
| GPT | Generative model that generates coherent and contextually appropriate text based on input prompts. |
| RoBERTa | Improved variant of BERT that incorporates additional training techniques to enhance its performance. |
Dialogue Systems and Chatbots
Components of dialogue systems
| Component | Description |
|---|---|
| Dialogue Manager | Orchestrates conversation flow, determines system actions, and maintains context. |
| Natural Language Understanding (NLU) | Extracts meaning from user inputs, comprehends intent, and classifies dialogue acts. |
| Natural Language Generation (NLG) | Generates coherent and contextually appropriate responses to user queries. |
Rule-based vs. machine learning-based dialogue systems
| Approach | Description |
|---|---|
| Rule-based Dialogue Systems | Rely on predefined rules and patterns for generating responses, offering control but limited flexibility. |
| Machine Learning-based Dialogue Systems | Leverage large datasets and advanced algorithms to learn from examples, handling complex conversations. |
Reinforcement learning for dialogue policy optimization
Reinforcement learning enables dialogue systems to optimize their dialogue policies through trial and error. The dialogue system interacts with users or simulated users, receiving feedback in the form of rewards. By exploring different actions and observing the rewards, the system learns to select actions that maximize long-term success. Reinforcement learning has shown promising results in improving dialogue systems’ performance and adaptability.
End-to-end trainable chatbot models
| Model | Description |
| Seq2Seq | Consists of an encoder and a decoder, used for chatbot applications and machine translation. |
| Transformer | Revolutionized NLP with self-attention mechanism, highly efficient for capturing contextual dependencies. |
NLP in Social Media Analysis
Challenges of Social Media Text Analysis
| Challenges | Description |
|---|---|
| Short Text | Analyzing microcontent demands specialized techniques to extract meaningful insights from limited text length. |
| Noise | Social media data often contains noise, such as typographical errors, slang, and emoticons. Robust preprocessing techniques are required for accurate analysis. |
| Informal Language | Users employ informal language, including colloquialisms and slang, requiring understanding and interpretation for accurate analysis. |
Sentiment Analysis in Social Media
Sentiment analysis is a powerful technique used to determine the polarity of social media text, categorizing it as positive, negative, or neutral. By analyzing sentiment, we gain insights into public opinion, brand perception, and customer sentiment. Let’s consider an example:
Example: “Just tried the new restaurant in town. The food was amazing, but the service was terrible!”
In this case, sentiment analysis can identify positive sentiment towards the food and negative sentiment towards the service, providing valuable feedback for restaurant owners and potential customers.
Named Entity Recognition in Social Media
Named Entity Recognition (NER) is a technique used to identify and classify named entities in social media text, such as names of people, organizations, locations, and other relevant entities. NER enables us to extract key information and understand the context of social media conversations. Let’s see an example:
Example: “Attending the #AIConference in San Francisco. Excited to hear from Elon Musk and visit Tesla’s headquarters!”
NER can identify “AIConference” as an event, “San Francisco” as a location, “Elon Musk” as a person, and “Tesla” as an organization, providing valuable insights into trending topics and influential figures in the AI industry.
Opinion Mining and Topic Detection from Social Media Data
Opinion mining focuses on extracting subjective information from social media data, enabling us to understand public sentiment towards specific topics or products. By analyzing user opinions and reviews, we can identify emerging trends and potential areas for improvement. Consider the following example:
Example: “The latest smartphone release has an amazing camera, but the battery life is disappointing.”
Opinion mining can reveal positive sentiment towards the camera feature and negative sentiment towards the battery life, providing valuable feedback for smartphone manufacturers.
Ethics and Bias in NLP
Bias and fairness issues in NLP algorithms
| Challenges | Examples |
|---|---|
| Gender bias in language models | Language models generating biased output |
| Racial bias in sentiment analysis systems | Sentiment analysis systems exhibiting bias |
NLP algorithms are not immune to bias, as they learn from human-generated data, which can inadvertently reflect societal biases. This poses risks, as biased algorithms can perpetuate discrimination, reinforce stereotypes, and exclude certain groups from fair treatment. Examples abound, such as gender bias in language models generating biased output or racial bias in sentiment analysis systems.
Addressing bias in training data and model outputs
| Challenges | Examples |
|---|---|
| Gender bias in language models | Language models generating biased output |
| Racial bias in sentiment analysis systems | Sentiment analysis systems exhibiting bias |
To mitigate bias in NLP algorithms, it is essential to tackle the root cause: biased training data. Steps must be taken to ensure diverse, representative datasets that encompass different demographics and perspectives. Additionally, techniques like data augmentation and algorithmic interventions, such as debiasing methods and fairness constraints, can help address bias in model outputs.
Ethical considerations in data collection and use
| Ethical Considerations | Importance |
|---|---|
| Informed consent | Respecting individuals’ rights and autonomy |
| Privacy protection | Safeguarding sensitive data |
| Data anonymization | Preventing the identification of individuals |
| Transparency and accountability | Ensuring responsible data governance |
| Ethical impact assessments | Evaluating potential harm of biased models |
Ethics play a crucial role in the data collection and use processes of NLP systems. Informed consent, privacy protection, and data anonymization are essential to respect individuals’ rights and maintain trust. Organizations must adhere to ethical guidelines, ensuring transparency, accountability, and responsible data governance. Moreover, considering the potential harm of biased models, deploying systems that undergo rigorous ethical impact assessments becomes imperative.
Responsible development and deployment of NLP systems
| Key Practices | Actions |
|---|---|
| Interdisciplinary collaboration | Involving researchers, developers, ethicists, and domain experts |
| Fairness evaluation | Utilizing open-source frameworks and tools for evaluating bias |
| Interpretability | Ensuring models provide understandable and transparent outputs |
| User feedback | Incorporating user perspectives and addressing concerns |
| Continuous monitoring | Iteratively improving systems and addressing bias throughout the lifecycle |
The responsible development and deployment of NLP systems involve an interdisciplinary approach. Collaboration between researchers, developers, ethicists, and domain experts can help uncover and mitigate potential biases early in the process. Open-source frameworks, guidelines, and tools can facilitate fairness evaluation, interpretability, and user feedback. It is crucial to continuously monitor and address bias during the system’s life cycle, allowing for iterative improvements.
Future Trends in NLP
| Heading | Description | Example | Benefit |
|---|---|---|---|
| Multimodal NLP: Text with Images, Video, and Audio | Multimodal NLP combines different modalities (text, images, video, audio) for enhanced understanding | An AI assistant analyzes spoken requests, images, and videos to provide relevant responses | Deeper context and understanding in domains like virtual assistants, chatbots, and multimedia |
| Explainable and Interpretable NLP Models | Models that provide transparency and insights into their decision-making process | Techniques like attention mechanisms and LIME identify important features for model interpretation | Better user trust, understanding, and identification of model strengths, limitations, and biases |
| Zero-Shot and Few-Shot Learning in NLP | Techniques for generalizing to unseen tasks or learning with limited labeled examples | Zero-shot learning: Sentiment analysis model trained on movie reviews classifies product reviews | Improved flexibility and adaptability of NLP models in real-world scenarios with limited data |
| Reinforcement Learning and Self-Supervised Learning in NLP | Techniques leveraging feedback and unlabeled data for improved performance and adaptability | Reinforcement learning in dialogue systems for generating appropriate responses based on feedback | Enhanced NLP model performance and efficiency through pre-training and fine-tuning on specific tasks |
Conclusion
Natural Language Processing has rapidly evolved and become an integral part of our lives, impacting numerous domains such as healthcare, customer service, education, and more. This article has aimed to provide a comprehensive guide to NLP, covering its key concepts, techniques, and applications. We explored the fundamental components of NLP, including tokenization, language modeling, and sentiment analysis, and delved into advanced topics such as machine translation, question answering, and text generation.
With the ever-growing advancements in AI and the increasing availability of NLP tools and libraries, the potential for further innovation and application of NLP is boundless. By harnessing the power of NLP, we can continue to enhance human-computer interaction, automate tasks, and gain valuable insights from the vast amount of textual data available. As the field of NLP progresses, it is an exciting time to be part of this journey, and we hope this guide has provided you with a solid foundation to explore and contribute to the fascinating world of Natural Language Processing.
FAQs
What is Natural Language Processing (NLP) and what are its primary goals?
- Natural Language Processing (NLP) is AI’s focus on human language interaction.
- Primary goals: understanding, generating, and facilitating communication with human language.
What are some of the challenges in NLP and how are they addressed?
- Ambiguity: Addressed through context analysis and leveraging language models.
- Named Entity Recognition (NER): Addressed using machine learning algorithms.
- Language Understanding: Addressed with sophisticated models capturing language nuances.
- Language Generation: Addressed with neural models and attention mechanisms.
How does text preprocessing contribute to the effectiveness of NLP models?
- Cleans text by removing noise and special characters.
- Tokenizes and normalizes text for analysis.
- Removes stop words from reducing noise.
- Enables numerical representation suitable for ML algorithms.
What are some popular statistical methods used in NLP and their applications?
- Naive Bayes: Text classification (sentiment analysis, spam detection).
- Hidden Markov Models (HMMs): Part-of-speech tagging, speech recognition.
- Conditional Random Fields (CRFs): Named Entity Recognition (NER).
- Latent Dirichlet Allocation (LDA): Topic modeling.
- Support Vector Machines (SVMs): Text classification, NER.
- Neural Networks: Language modeling, machine translation, sentiment analysis.
How can rule-based systems be utilized in NLP tasks like named entity recognition?
- Define linguistic patterns or domain-specific rules.
- Capture entity patterns (capitalization, word sequences, semantics).
- Effective for consistent entity patterns or specific domains.
- Complementary to machine learning models.
Related Articles
View All
AI & ML
Why Businesses Are Hiring OpenAI Consultants and How Certification Gives You the Edge
Businesses are increasingly hiring OpenAI consultants to integrate AI into operations, improve productivity, and drive innovation. Learn why demand is rising and how professional certification can help you stand out in a competitive AI job market.

AI & ML
Industries Hiring OpenAI Consultants the Most: Healthcare, Finance, Legal & More
Organizations across healthcare, finance, legal, retail, manufacturing, and other sectors are hiring OpenAI consultants to implement AI solutions, automate workflows, and improve business operations. Discover which industries offer the strongest demand in 2026.

AI & ML
OpenAI Consulting as a Freelance Career: How to Land Clients and Build a Practice
Freelance OpenAI consulting is becoming a high-demand career as businesses seek experts to implement AI solutions. Learn how to find clients, build a strong portfolio, price your services, and grow a successful consulting practice.
Trending Articles

Top 5 DeFi Platforms
Explore the leading decentralized finance platforms and what makes each one unique in the evolving DeFi landscape.
What is AWS? A Beginner's Guide to Cloud Computing
Everything you need to know about Amazon Web Services, cloud computing fundamentals, and career opportunities.

Can DeFi 2.0 Bridge the Gap Between Traditional and Decentralized Finance?
The next generation of DeFi protocols aims to connect traditional banking with decentralized finance ecosystems.