The Journey Behind the AI Explosion: A Quick View

![]()
In 2014, Google made a major move in the tech industry by acquiring the UK-based artificial intelligence (AI) start-up DeepMind for a reported $500 million. The acquisition was significant for several reasons, including its potential impact on the development of AI technologies and the future direction of Google as a company.

DeepMind was founded in 2011 and quickly gained a reputation as one of the most innovative and forward-thinking AI start-ups in the world. Its team of researchers and engineers was responsible for several groundbreaking developments in the field of AI, including the creation of algorithms that could teach themselves to play video games and the development of AI models that could accurately predict the structure of proteins.
One of the most interesting aspects of the acquisition was its potential impact on the development of AI technologies. Google had already made significant strides in this area, with its AI-powered search engine, Google Assistant, and other AI-driven products. With DeepMind on board, Google was in a position to make even greater advances in the field, potentially leading to the creation of more powerful and sophisticated AI systems.
 Generative Adversarial Networks, or GANs, are a class of deep learning algorithms that are used to generate new data that is similar to a given dataset. GANs have become increasingly popular in recent years due to their ability to create realistic images, videos, and even audio. Generative Adversarial Networks were first introduced in 2014 by Ian Goodfellow and his colleagues in a paper titled “Generative Adversarial Networks”.
Generative Adversarial Networks, or GANs, are a class of deep learning algorithms that are used to generate new data that is similar to a given dataset. GANs have become increasingly popular in recent years due to their ability to create realistic images, videos, and even audio. Generative Adversarial Networks were first introduced in 2014 by Ian Goodfellow and his colleagues in a paper titled “Generative Adversarial Networks”.
At their core, GANs consisted of two neural networks: a generator and a discriminator. The generator was responsible for creating new data that is similar to the given dataset, while the discriminator was responsible for identifying whether a given piece of data is real or fake.
One of the most interesting aspects of GANs was their ability to generate new data that is similar to the original dataset but has unique variations. For example, a GAN trained on a dataset of human faces could generate new faces that are similar to those in the original dataset but have unique features such as different hairstyles or facial expressions.
In 2015, Google released a new image generator known as DeepDream. This revolutionary program utilized advanced artificial intelligence techniques to produce breathtaking and surreal images. Its release marked a significant milestone in the development of AI technology and showcased the power and potential of these cutting-edge algorithms.
DeepDream was developed by a team of Google engineers led by Alexander Mordvintsev, Michael Tyka, and Christopher Olah. The program was designed to utilize a type of AI known as a neural network, which is capable of learning and processing information in a way that is similar to the human brain. By training this neural network on a vast library of images, the DeepDream program was able to generate its own unique images based on patterns and shapes that it identified within the original data.
The results of the DeepDream program were truly astonishing. Users could input any image they desired, and the program would then generate a dreamlike, hallucinogenic version of the original image. These images were characterized by intricate and detailed patterns, swirling colors, and surreal shapes that seemed to warp and twist in unexpected ways.
![]()
In 2015, a group of the most brilliant minds in the tech industry came together to establish OpenAI, the nonprofit artificial intelligence research company that would push the boundaries of AI and transform the world as we know it. OpenAI was founded with the mission of creating artificial intelligence that would benefit humanity as a whole, and the organization quickly gained attention for its pioneering work in the field of AI.
From the outset, OpenAI recognized that AI had the potential to transform industries, revolutionize the way we live and work, and even solve some of the world’s most pressing problems. The company’s early work focused on developing machine learning algorithms that could analyze and understand human language. This research led to the creation of the now-famous GPT (Generative Pre-trained Transformer) language models, which revolutionized the field of natural language processing.
OpenAI launched GPT-1, an artificial intelligence language model in 2018 that would change the game for natural language processing. This revolutionary tool marked a turning point in the field of AI, providing the foundation for subsequent models that would go on to achieve even greater feats. With the ability to generate coherent text that mimicked human language patterns, it quickly became a go-to tool for content creators, marketers, and researchers alike. Its success was due in large part to its sophisticated neural network architecture, which enabled it to learn from massive amounts of data in order to improve its language generation capabilities over time.
One of the key features of GPT-1 was its versatility. It could be trained on a wide range of data sets, from news articles to novels, allowing it to generate text that matched the style and tone of different genres. Its ability to generate human-like language also made it an effective tool for chatbots and other conversational interfaces.
Despite its limitations, it marked the beginning of a new era in natural language processing, one that has since been marked by a rapid pace of innovation and ever-increasing capabilities. Today, GPT models are at the forefront of AI language processing, enabling new applications and use cases that were once thought impossible.

In 2015, a group of tech enthusiasts founded OpenAI with the aim of advancing artificial intelligence in a responsible and beneficial manner. Fast forward to a few years later, and OpenAI Five had emerged as one of the most revolutionary and groundbreaking AI systems to date.
OpenAI Five is an AI system designed to play complex strategy games at a superhuman level. This system has been used to play games such as Dota 2, one of the most popular online multiplayer games worldwide. With the ability to compete against the world’s best Dota 2 players, OpenAI Five has already made waves in the gaming world.
One of the most significant aspects of OpenAI Five is its ability to learn and improve through experience. This AI system has the ability to play thousands of games against itself, allowing it to gain invaluable experience and learn from its mistakes. This self-improvement mechanism is what makes OpenAI Five truly unique and a force to be reckoned with in the gaming world.

In 2018, Google introduced a groundbreaking language model called BERT, which stands for Bidirectional Encoder Representations from Transformers. BERT is a neural network-based model that is capable of understanding the nuances of natural language by processing words in context. This breakthrough development has significantly improved the accuracy of natural language processing (NLP) applications, enabling machines to understand human language with more precision.
BERT was developed by a team of researchers at Google, led by Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. The team’s goal was to create a more sophisticated language model that could better capture the complex relationships between words in natural language text. One of the key advantages of BERT is its ability to handle ambiguity in language. By processing words in context, BERT can distinguish between words that have different meanings depending on their context.
For example, the word “bank” could refer to a financial institution or the side of a river, and BERT is able to determine which meaning is more appropriate based on the context of the sentence. BERT’s impact on NLP has been significant, and it has become a widely used model in various applications, including sentiment analysis, question answering, and text classification. In fact, BERT has achieved state-of-the-art performance on a number of benchmarks, including the Stanford Question Answering Dataset (SQuAD) and the GLUE benchmark.
In 2019, OpenAI released its highly anticipated GPT-2 language model. The model was trained on a massive corpus of text, allowing it to generate incredibly realistic and coherent text. GPT-2 quickly gained attention from researchers, businesses, and the general public alike. One of the most notable investors in GPT-2 was Microsoft, who invested a whopping $2 billion in the project. This investment reflected the immense potential that GPT-2 held for the future of NLP and AI in general.
GPT-2 was designed to excel at a wide range of language tasks, including language translation, text summarization, and even writing entire articles or stories. The model’s success was largely due to its ability to generate text that was both coherent and highly engaging. This made it a valuable tool for businesses looking to create compelling marketing copy, journalists looking to generate headlines, and even writers looking for inspiration.
In addition to its commercial potential, GPT-2 also held immense value for researchers in the field of NLP. The model’s ability to generate highly coherent and realistic text allowed researchers to explore new avenues in the field of language processing. This could potentially lead to new breakthroughs in the field and push the boundaries of what was possible with AI.
RoBERTa, founded in 2019, is an innovative natural language processing (NLP) system that has taken the field by storm. This model, built upon the success of BERT, has achieved state-of-the-art performance on a wide range of NLP tasks. In this article, we will take a closer look at RoBERTa, its architecture, and its impact on the NLP landscape.
RoBERTa is a self-supervised learning system that is pre-trained on large amounts of text data to learn contextualized word representations. The model was developed by Facebook AI Research (FAIR) and is based on the BERT architecture. However, RoBERTa has several important improvements over BERT that make it a more powerful NLP system.
One of the main improvements of RoBERTa is the use of a larger training corpus. BERT was pre-trained on a large corpus of text data, but RoBERTa was trained on an even larger corpus of text, which allowed it to learn more nuanced and complex representations of language. RoBERTa was also trained with longer sequences of text, which enabled it to learn better representations of longer documents. RoBERTa has achieved state-of-the-art performance on a wide range of NLP tasks, including sentiment analysis, question answering, and language modeling. It has also been used in a variety of applications, including chatbots, search engines, and automated content generation.
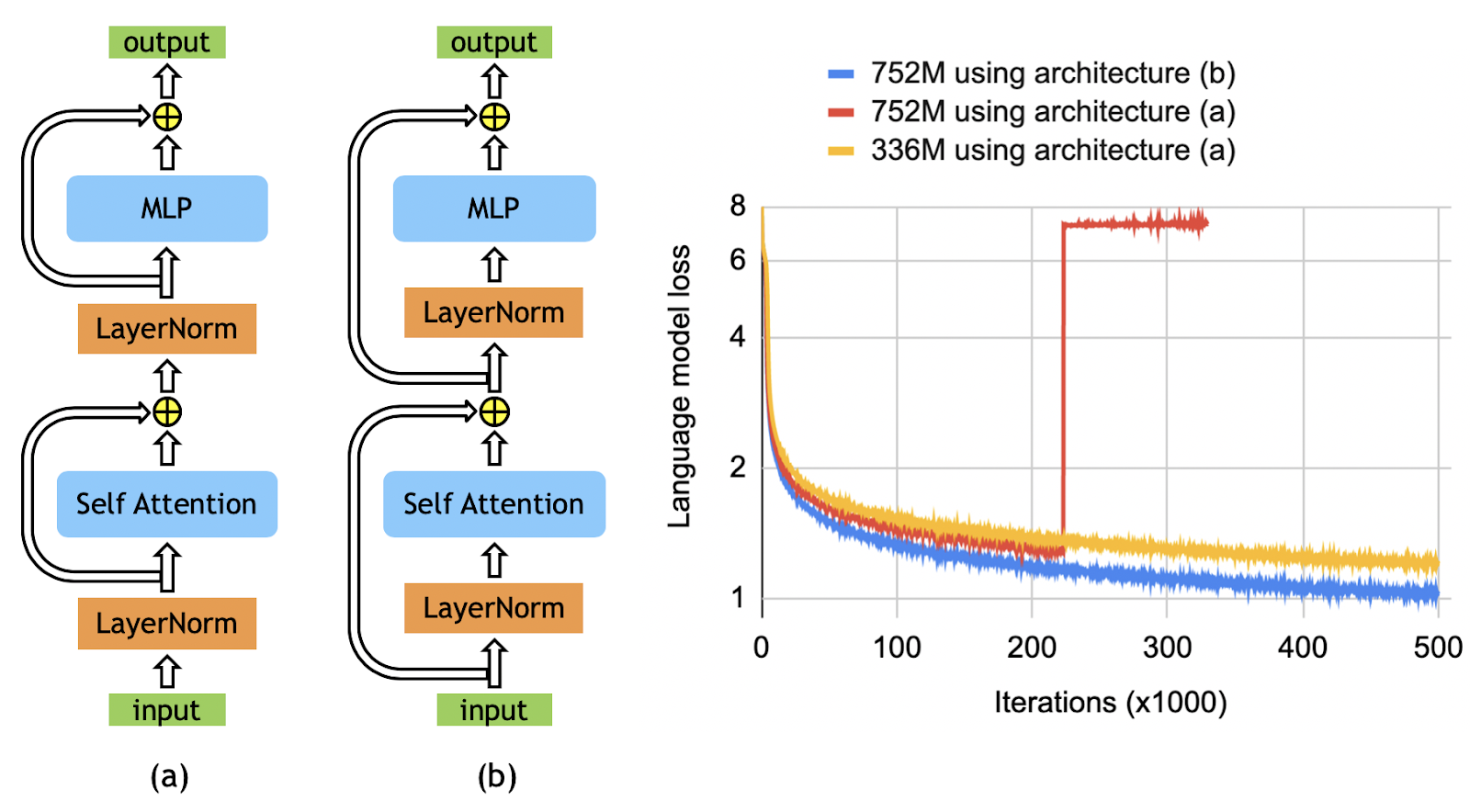 Megatron-LM, the powerful library for training language models, was founded in 2019. This library has become a game-changer in the field of natural language processing (NLP) due to its ability to train some of the largest language models ever created.
Megatron-LM, the powerful library for training language models, was founded in 2019. This library has become a game-changer in the field of natural language processing (NLP) due to its ability to train some of the largest language models ever created.
Using Megatron-LM, researchers and developers can now train models with billions of parameters, leading to significant improvements in language generation, translation, and understanding. Megatron-LM has made it possible to create some of the most advanced NLP models that have revolutionized the way we interact with computers.
The library was developed by NVIDIA, a leading company in artificial intelligence (AI) and machine learning (ML) technologies. NVIDIA created Megatron-LM to make it easier for researchers to train large language models on distributed computing systems such as NVIDIA GPUs. It can distribute the training of a single model across multiple GPUs and multiple machines, reducing training time significantly. This scalability makes it possible to train some of the largest language models ever created, such as GPT-3, which has 175 billion parameters.
OpenAI’s GLIDE, Guided Language-to-Image Diffusion for Generation and Editing, was founded in 2022 and represents a significant step forward in the field of text-to-image generation. GLIDE uses a 3.5 billion parameter diffusion model that employs a text encoder to condition on natural language descriptions, enabling it to automatically generate photorealistic images from text prompts.
One of the most exciting aspects of GLIDE is its ability to change existing images through natural language text prompts, adding objects, shadows, reflections, conducting image inpainting, and more. Additionally, GLIDE can convert basic line drawings into photorealistic photos, and it has powerful zero-sample production and repair capabilities for complicated circumstances.
Human assessors have preferred GLIDE’s output images to those of DALL-E, despite GLIDE’s smaller size, with only one-third of DALL-E’s 12 billion parameters. GLIDE requires less sampling delay and does not require CLIP reordering. Generating images from text inputs requires specialized skills and many hours of labor, but GLIDE empowers humans to create rich and diverse visual content with unprecedented ease. GLIDE also allows for easier iterative refinement and fine-grained control of the generated images, making it a valuable tool for artists and designers.
Stable Diffusion is a deep learning model that has been making waves since its release in 2022. This latent text-to-image diffusion model, developed by Stability AI in collaboration with academic researchers and non-profit organizations, has brought about a paradigm shift in the field of image generation. With the ability to generate photo-realistic images based on any text input, the model has empowered billions of people to create stunning art within seconds.
Stable Diffusion’s technical license was released by the CompVis group at Ludwig Maximilian University of Munich, under a Creative ML OpenRAIL-M license that allows for commercial and non-commercial usage. The license emphasizes ethical and legal use of the model as the responsibility of the user and must accompany any distribution of the model. The model card outlines the limitations of the model and welcomes feedback from the community to improve this technology.
The AI-based Safety Classifier, included in the overall software package, understands concepts and other factors in generations to remove outputs that may not be desired by the user. The parameters of this classifier can be readily adjusted and the community’s input is welcomed to improve its effectiveness. While image generation models are powerful, they still have room for improvement to better understand how to represent what we want.
DALL-E 2 was officially announced by OpenAI in April 2022, and it was designed to generate more realistic images at higher resolutions. The new model is also capable of combining concepts, attributes, and styles, allowing for even greater creativity and flexibility in image generation. Initially, OpenAI had restricted access to DALL-E 2 due to concerns about ethics and safety. However, in July 2022, the software entered into a beta phase, and invitations were sent to 1 million waitlisted individuals. Users could generate a certain number of images for free every month and could purchase more if needed. And as of September 2022, DALL-E 2 was opened to anyone, and the waitlist requirement was removed.
One of the most exciting things about DALL-E 2 is that it has been made available as an API, which means developers can integrate the model into their own applications. Microsoft, for instance, has already implemented DALL-E 2 in their Designer app and Image Creator tool included in Bing and Microsoft Edge. CALA and Mixtiles are among other early adopters of the DALL-E 2 API. The API operates on a cost per image basis, with prices varying depending on image resolution. Volume discounts are available to companies working with OpenAI’s enterprise team.
DALL-E 2’s “inpainting” and “outpainting” capabilities are particularly impressive. These features use context from an image to fill in missing areas using a medium consistent with the original, following a given prompt. For example, this can be used to insert a new subject into an image, or expand an image beyond its original borders. According to OpenAI, “Outpainting takes into account the image’s existing visual elements – including shadows, reflections, and textures – to maintain the context of the original image.”
DeepMind unveiled the Chinchilla language mode in 2022l shortly before Google introduced its PaLM model with a whopping 540 billion parameters. What makes Chinchilla unique is its size: the team focused on increasing the amount of training data rather than the number of parameters, a strategy that proved successful. With only 70 billion parameters, Chinchilla was trained with a massive 1.3 trillion tokens of data. By scaling the model size and training dataset size equally, the researchers were able to optimize Chinchilla’s performance with a relatively low computational budget.
Compared to Gopher (280 billion parameters) and GPT-3 (175 billion parameters), Chinchilla significantly outperformed these models on a range of downstream evaluation tasks. It even achieved an average accuracy of 67.5% on the MMLU benchmark, which is a 7% improvement over Gopher.
The trend in language model training has been to increase the number of parameters, with the largest model currently boasting 530 billion parameters. However, this race to create larger models has resulted in models that are undertrained and underperforming compared to what could be achieved with the same compute budget.
In 2022, Meta AI made a groundbreaking move by releasing Open Pretrained Transformer (OPT-175B), a language model with an astonishing 175 billion parameters, trained on publicly available datasets. OPT-175B is a massive language technology system, similar in performance to GPT-3, and was created with energy efficiency in mind, allowing it to be produced with just 1/7th the carbon footprint of its predecessor.
The release included both the pretrained models and the code required to train and use them, making it the first time that such a large language model has been made available in its entirety. The model is released under a noncommercial license for research purposes, and access is granted to academic researchers, those affiliated with organizations in government, civil society, and academia, as well as industry research laboratories worldwide.
OPT-175B has been trained on a vast range of open-source datasets for standard language model tasks, such as natural language generation and dialogue, along with the ability to detect biases and hate speech. The OPT line of models provides a set of freely usable language models that are comparable to existing models, bypassing the need for machine learning engineers to endure the exhausting initial training phase.
In 2022, Google unveiled the LaMDA 2 AI system at the Google I/O keynote, which is an enhanced version of the original LaMDA designed for dialogue applications. Unlike the original, which could engage in short conversations, LaMDA 2 is capable of long, human-like conversations and can provide accurate responses in easy-to-understand sentences. Like all AI systems, LaMDA 2 was fed a lot of datasets to learn and train on how humans converse with each other. It analyzed petabytes of data and was trained to produce human-like answers. Recent advancements in large neural networks trained for language understanding and generation have achieved impressive results across a wide range of tasks.
For example, GPT-3 showed that large language models (LLMs) can be used for few-shot learning and can achieve impressive results without large-scale task-specific data collection or model parameter updating. Meanwhile, PaLM, the Pathways Language Model, is a 540-billion parameter, dense decoder-only Transformer model trained with the Pathways system. It is the first large-scale use of the Pathways system to scale training to 6144 chips, the largest TPU-based system configuration used for training to date. PaLM achieves state-of-the-art few-shot performance across most tasks, by significant margins in many cases.
PaLM was trained using a combination of English and multilingual datasets that include high-quality web documents, books, Wikipedia, conversations, and GitHub code. The model achieves a training efficiency of 57.8% hardware FLOPs utilization, the highest yet achieved for LLMs at this scale.
In 2022, Yandex, the Russian multinational technology company, released the world’s largest GPT-like neural network, called YaLM. YaLM, short for Yandex Language Model, was founded with the aim of generating and processing text with the help of language models. This neural network is available for free under the Apache 2.0 license, which permits both research and commercial use.
YaLM 100B, the latest addition to the YaLM family, contains an unprecedented 100 billion parameters, making it the largest GPT-like model available in open-source. The model was trained on a vast pool of online texts, books, and countless other sources in both English and Russian, totaling about 1.7 TB of data. The training process took an impressive 65 days to complete on a cluster of 800 A100 graphics cards.
Language models from the YaLM family are based on the principles of constructing a text and generate new ones based on their knowledge of linguistics and the world. The neural network can generate texts ranging from poems to answers and classify them based on their style of speech. Yandex utilizes YaLM neural networks in over 20 projects, including its search engine and voice assistant Alice. These language models help support staff respond to requests, generate advertisements and site descriptions, and prepare quick answers in Yandex Search.

Midjourney is an independent research lab that is revolutionizing the field of AI-generated images. The San Francisco-based company was founded by David Holz, co-founder of Leap Motion, in the year 2022. Since then, Midjourney has been dedicated to exploring new mediums of thought and expanding the imaginative powers of the human species.
Midjourney’s image generation platform creates images from natural language descriptions, or prompts, just like OpenAI’s DALL-E and Stable Diffusion. The tool is currently in open beta, which it entered on July 12, 2022. Midjourney has 11 full-time staff and an incredible set of advisors who are dedicated to improving its algorithms and releasing new model versions every few months.
The company has been working on improving its algorithms, releasing new model versions every few months. Version 2 of their algorithm was launched in April 2022 and version 3 on July 25. On November 5, 2022, the alpha iteration of version 4 was released to users and on March 15, 2023, the alpha iteration of version 5 was released. The Midjourney team is led by David Holz, who sees artists as customers, not competitors of Midjourney. According to him, artists use Midjourney for rapid prototyping of artistic concepts to show to clients before starting work themselves.
Gato is an AI system developed by DeepMind, a company dedicated to the advancement of artificial intelligence. The system was founded in 2022 and is capable of performing a wide variety of tasks, making it a generalist AI rather than an expert in a specific area.
What sets Gato apart from other AI systems is its ability to perform more than 600 different tasks. These tasks range from playing video games to captioning images and even moving real-world robotic arms. Gato is a multi-modal, multi-task, multi-embodiment generalist policy, meaning it can perform a diverse range of tasks in different environments. Gato’s architecture is based on the Transformer model, which is similar to OpenAI’s GPT-3. This model has been successful in complicated reasoning tasks such as summarizing texts, categorizing objects in photos, producing music, and analyzing protein sequences.
The system learns by example, ingesting billions of words, images, button presses, joint torques, and more in the form of tokens. These tokens enable Gato to understand and perform different tasks. One of Gato’s most impressive features is its parameter count, which is orders of magnitude lower than single-task systems like GPT-3. Parameters are components learned from training data that describe the system’s ability to solve a problem. Gato’s low parameter count allows it to be more efficient and effective than other AI systems.
Scalability.ai, an open-source AI company, announced in 2022 that it raised an impressive $101 million in a seed round. The round was led by Coatue and Lightspeed Venture Partners, with O’Shaughnessy Ventures LLC also participating. This puts the company’s value at $1 billion post-money. The company was founded in 2020 by Emad Mostaque, who is a mathematician and computer science graduate from Oxford.
Scalability.ai’s primary goal is to develop open AI models for images, language, audio, video, and 3D, catering to both consumers and enterprises worldwide. The company’s unique approach is to empower developer communities by putting the power back in their hands. Their product, Stable Diffusion, is a free and open-source text-to-image generator that has already been downloaded and licensed by over 200,000 developers globally. Scalability.ai’s consumer-facing product, DreamStudio, has also gained significant traction, with over a million registered users from more than 50 countries who have created over 170 million images collectively.
Although the company has achieved tremendous success, it has not been without controversy. The release of Stable Diffusion, which was trained on a data set that included copyrighted works, has been used to create objectionable content like graphic violence and non-consensual celebrity deepfakes. Getty Images even banned the upload of content generated by systems like Stable Diffusion due to fears of intellectual property disputes. U.S. House Representative Anna G. Eshoo (D-CA) has written a letter to the National Security Advisor and the Office of Science and Technology Policy, urging them to address the release of “unsafe AI models” that do not moderate content made on their platforms.
ChatGPT, a language model trained by OpenAI, was founded in the year 2022. It was designed to cater to the needs of people who were looking for an intelligent and versatile AI language model that could assist them in various tasks such as writing, answering questions, and providing information on various topics.
From the very beginning, ChatGPT aimed to be the best in the industry by providing top-notch services that were not only accurate but also highly engaging and compelling. The team behind ChatGPT worked tirelessly to train the model using the latest NLP techniques, ensuring that it could understand and respond to human language in the most natural way possible.
One of the unique features of ChatGPT is its ability to seamlessly transition between topics and provide answers to a wide range of questions. This was made possible by the extensive research and development that went into the model’s training, ensuring that it could handle a vast array of topics with ease. Since its founding in 2022, ChatGPT has gained a reputation for being one of the most reliable and versatile AI language models available. Its ability to provide accurate and engaging answers to a wide range of questions has made it a popular choice among users who are looking for a powerful and intuitive language model.
Related Articles
View All
AI & ML
LongCat AI Explained: How Meme Culture, Generative AI, and Web3 Communities Are Converging
LongCat AI blends open-source generative models, meme-native branding, and Web3-style community building across coding, video, agents, and avatars.

AI & ML
What Is LongCat AI? A Beginner's Guide to the Viral AI Trend and Its Real-World Use Cases
LongCat AI is Meituan's open source AI ecosystem for chat, coding, long-form video, and avatar generation. Learn how it works and where it fits.

AI & ML
China AI Tools: Free vs Paid Options for Builders, Creators, and Enterprises
Compare free and paid China AI tools for coding, content creation, agents, Web3 workflows, enterprise use, cost, compliance, and support.
Trending Articles
The Role of Blockchain in Ethical AI Development
How blockchain technology is being used to promote transparency and accountability in artificial intelligence systems.

Can DeFi 2.0 Bridge the Gap Between Traditional and Decentralized Finance?
The next generation of DeFi protocols aims to connect traditional banking with decentralized finance ecosystems.
Claude AI Tools for Productivity
Discover Claude AI tools for productivity to streamline tasks, manage workflows, and improve efficiency.