Claude AI for Kubernetes Operations: Debugging, YAML Validation, and Cost-Optimized Scaling
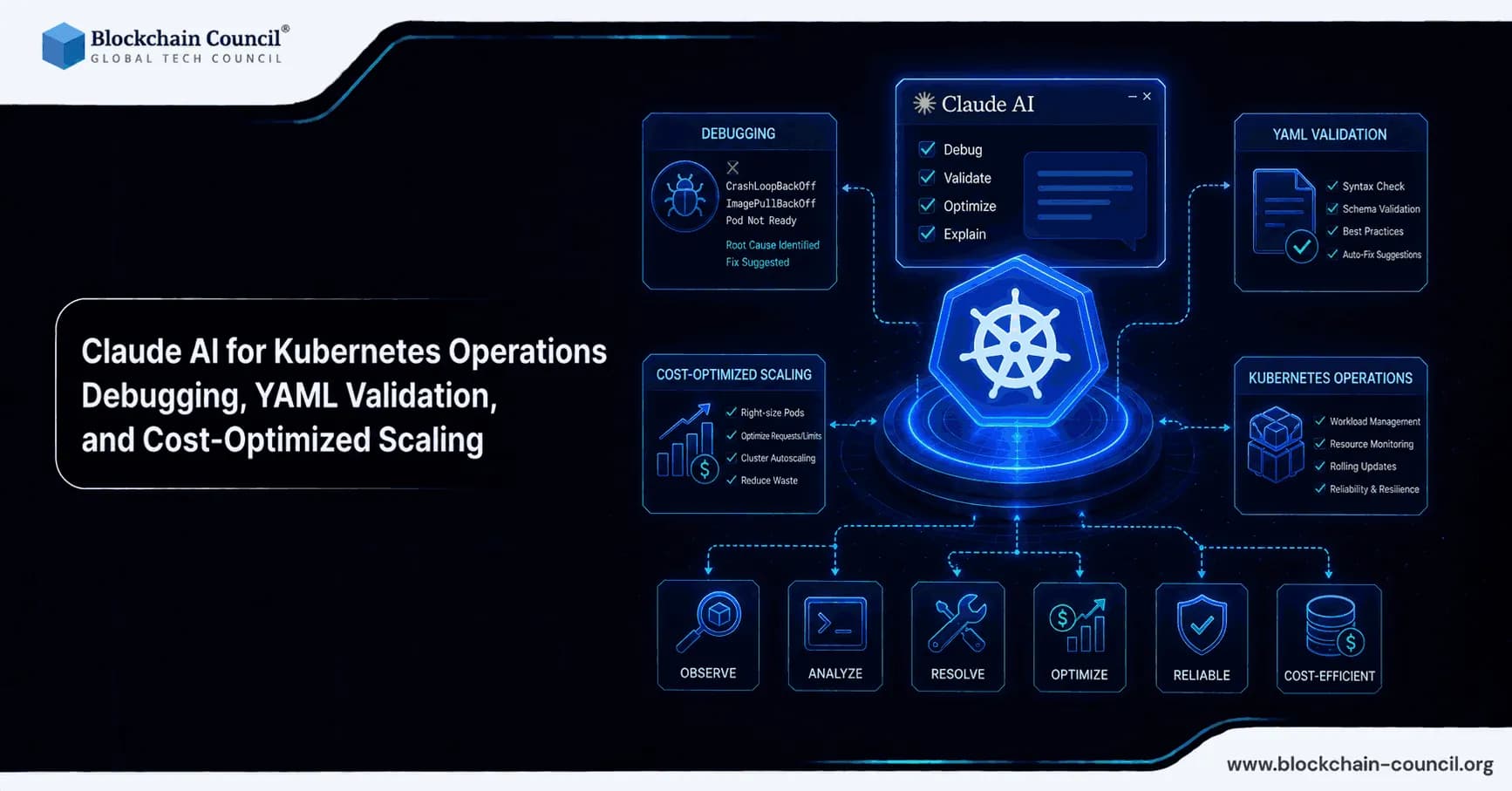
Claude AI for Kubernetes operations is becoming a practical layer in modern SRE and platform engineering workflows. Rather than replacing experienced operators, Claude-based tooling (notably Anthropic's Claude Code) acts as an AI copilot that translates intent into safe, repeatable operational steps - particularly for debugging, YAML validation, and cost-optimized scaling. Early 2026 practitioner reports describe a consistent pattern: teams encode their conventions into reusable skills, run read-heavy diagnostics quickly, and require explicit approval for write actions. Use Claude AI to troubleshoot Kubernetes clusters, validate YAML manifests, optimize resource allocation, and reduce cloud infrastructure costs by building expertise through an AI certification, automating Kubernetes operations and infrastructure analysis using a Python certification, and scaling DevOps-driven businesses with a Digital marketing course.
What Claude AI Looks Like in Day-to-Day Kubernetes Operations
In Kubernetes, speed is rarely the only goal. Accuracy, safety, and consistent execution matter more, especially across multiple environments. Claude Code has gained traction because it supports conversational interaction while still invoking real tools such as kubectl and OpenTofu commands like tofu plan. A common safety model is read-only by default, with human approval gates required for any write or apply operations. This supports a zero-trust operational posture where the AI can investigate freely but cannot change production silently.

A key differentiator is the use of custom skills - predefined scripts and workflows documented in files like CLAUDE.md and configured through .claude/settings.json. In practice, skills capture institutional knowledge: naming conventions, namespace rules, cluster context checks, allowed commands, and standardized output formats. This approach reduces prompt ambiguity and lowers the risk of unsafe suggestions.
Deployment Patterns: Local, Remote, and In-Cluster
Teams commonly start with local usage, then progress to remote or in-cluster deployments. An emerging pattern is running Claude Code as a persistent pod using Helm charts, enabling controlled access via kubectl exec. This model supports multiple authentication options (for example, Anthropic API keys or other identity providers) and allows centralizing skills so the entire team benefits from consistent workflows.
For observability, some operators pair Claude-driven workflows with eBPF-based monitoring to gain visibility into subprocess behavior - for example, external calls made during troubleshooting - without requiring application code changes. This is useful when you want to treat the AI agent as another auditable workload with measurable behavior.
Debugging with Claude AI for Kubernetes Operations
Kubernetes debugging typically follows a multi-step sequence: check cluster health, identify failing workloads, inspect events, review logs, confirm storage and certificate status, and verify recent changes. Claude AI adds value when it compresses these sequences into repeatable workflows with standardized outputs.
1) Cluster Health Checks in Seconds
Practitioner-reported skills like k8s-status generate quick, structured health reports across common failure domains:
Node readiness and scheduling pressure
Pending PVCs and storage binding issues
Failed jobs and backoff patterns
Certificate expiration risk
High-level summary states such as HEALTHY, WARNING, or CRITICAL
Rather than returning long, noisy outputs, the skill produces condensed results and suggests the next command - for example, sorting events by timestamp to surface the earliest root cause. This saves time and reduces the chance of missing a key signal within a wall of text.
2) Pod Troubleshooting with Context-Aware Log Collection
Log retrieval is deceptively error-prone: wrong namespace, wrong container, wrong context, or missing the previous container logs in CrashLoopBackOff scenarios. Skills like k8s-logs apply context-aware flags (for example, --previous or error filtering) and return a summarized diagnosis with counts and likely causes. Skills marketplaces are also emerging that focus on common failure cases like CrashLoopBackOff and image pull errors, while preventing unsafe behaviors such as printing secrets to output.
3) Authentication and Access Failures
Many outages begin as access problems: expired credentials, incorrect kubeconfig, or cloud provider authentication drift. Some workflows guide re-authentication steps for managed Kubernetes services and validate the active context before any action is taken. While this may seem basic, it eliminates a frequent class of mistakes - running the correct command against the wrong cluster.
YAML Validation and Safer Configuration Changes
Kubernetes YAML errors are a persistent source of incidents: incorrect resource limits, mis-specified probes, invalid selectors, and drift between Helm values and rendered manifests. Claude AI for Kubernetes operations is most useful when it behaves like a reviewer that checks intent, validates manifests, and proposes minimal, precise edits.
Common YAML Failure Patterns Claude Can Catch
Resource misconfiguration: limits set too low (leading to OOMKilled) or requests set too high (leading to scheduling failures)
Probe issues: readiness and liveness endpoints mis-specified, causing restarts or broken traffic routing
Selector mismatches: services not targeting pods due to label drift
Namespace and context mistakes: applying manifests into the wrong environment
Using Plan-First Workflows with OpenTofu
For infrastructure changes tied to Kubernetes operations, Claude Code can incorporate tofu plan to preview changes before they are applied. This enables a safer workflow where the AI proposes adjustments (for example, a memory limit increase or a scaling change), then verifies impact using a non-destructive plan. A tofu apply is only executed after human review.
This plan-first pattern aligns well with enterprise change management because it produces artifacts that can be reviewed in pull requests and linked to tickets. It also keeps configuration changes small and auditable.
Cost-Optimized Scaling Strategies with Claude AI for Kubernetes Operations
Scaling is not only about increasing replicas. It also involves controlling spend across compute, storage, and operational overhead. In AI-assisted operations, there is an additional cost dimension: token usage for API-driven assistants. Current practice highlights three levers: token efficiency, previewing scaling impact, and hibernating idle automation.
1) Token-Efficient Operational Skills
Some Kubernetes operations skill toolkits report up to 70% token savings by returning condensed outputs rather than raw command dumps. This matters when you rely on an API-based assistant across many clusters and repeated checks. Token efficiency improves:
Daily health checks across environments
Incident response loops where multiple commands run in sequence
Audit and compliance summaries that would otherwise require verbose log output
2) Scaling with Previews, Not Guesses
When scaling involves infrastructure-as-code, tofu plan functions as a cost control mechanism. Rather than applying a change and discovering downstream impacts (such as node pool expansion), operators can review a plan and adjust the proposal before committing. For Kubernetes-native scaling, Claude can also help interpret HPA behavior, identify whether bottlenecks are CPU, memory, I/O, or external dependencies, and recommend targeted changes - for example, right-sizing requests before increasing replicas.
3) Observability-Driven Right-Sizing and AI Agent Governance
eBPF-based observability has been used to monitor subprocess activity created by Claude-driven workflows, providing visibility into what the agent executes and how it behaves. This supports right-sizing in two ways:
Performance: identify slow commands or noisy diagnostic loops
Cost: understand compute and network overhead from automated troubleshooting routines
4) Kubernetes Sandboxes and Hibernation for Agent Fleets
A broader industry trend involves building scalable AI sandboxes on Kubernetes using CRDs and PVC-based hibernation. The approach keeps agent state available while pausing compute for idle agents, then restoring quickly when needed. Practitioner analysis suggests this can support large-scale agent fleets by reducing wasted runtime while preserving operational context.
Safety and Governance: Why Claude Is Treated as a Copilot
Industry guidance frames Claude Code as a copilot, not a replacement. The main governance principles observed in real-world implementations include:
Read-generous, write-cautious: investigation is straightforward, changes require approval
Context enforcement: always confirm cluster, namespace, and environment before acting
Skills as policy: forbid dangerous commands and encode safe defaults
Structured outputs: short, consistent summaries reduce misinterpretation
This safety-first design directly addresses common concerns about AI errors in production operations. Skills marketplaces are moving toward verified, token-efficient scripts, which can reduce both operational risk and spend.
How to Get Started: A Practical Adoption Roadmap
Start with read-only diagnostics: health checks, events, logs, and resource summaries.
Codify conventions in CLAUDE.md: namespaces, naming rules, required labels, and escalation steps.
Add skill workflows gradually: one reliable workflow per incident class (CrashLoopBackOff, pending PVCs, cert expiry).
Adopt plan-first change management: use tofu plan or GitOps previews before any apply operation.
Measure cost and latency: track token usage, runtime overhead, and the effect on mean time to resolution (MTTR).
Learn how Claude AI can improve Kubernetes operations with intelligent debugging, deployment validation, autoscaling recommendations, and infrastructure optimization by mastering AI-powered DevOps through an AI certification, building cloud automation systems using a Node JS Course, and promoting scalable cloud solutions using an AI powered marketing course.
Future Outlook
The trajectory for 2026 and beyond points toward deeper integrations: native telemetry hooks into Prometheus-style monitoring, more standardized skill registries, and hybrid workflows that combine intent-based tooling like kubectl-ai with infrastructure-as-code previews in OpenTofu. Industry analysts also forecast significant growth in agentic automation across operations by 2027, with governance and verification becoming central differentiators between mature and immature implementations.
Conclusion
Claude AI for Kubernetes operations delivers the most value when it makes proven workflows faster, safer, and cheaper: structured debugging, high-signal YAML validation, and cost-optimized scaling strategies that rely on previews and observability. The effective pattern is not free-form prompting. It is disciplined operational engineering - skills that encode standards, guardrails that require human approval for changes, and measurable improvements in time-to-diagnosis, configuration correctness, and infrastructure cost control.
FAQs
1. What is Claude AI for Kubernetes operations?
Claude AI for Kubernetes operations means using Claude-based tools to support debugging, YAML validation, and scaling workflows. It acts as an AI copilot that helps operators investigate issues, summarize findings, and suggest safe next steps. It is designed to assist SRE and platform teams, not replace them.
2. How does Claude AI help Kubernetes teams?
Claude AI helps Kubernetes teams by turning repeated operational tasks into structured workflows. It can assist with checking cluster health, reviewing logs, validating manifests, and interpreting scaling problems. This reduces manual effort while keeping human approval for risky actions.
3. Why is Claude treated as a copilot in Kubernetes operations?
Claude is treated as a copilot because production Kubernetes environments require accuracy, safety, and human judgment. It can investigate and recommend actions, but write operations should require approval. Letting AI freely change production would be bold, in the same way juggling knives during an earthquake is bold.
4. What is the read-only default model?
The read-only default model allows Claude to inspect Kubernetes resources without making changes. It can run diagnostic checks, gather logs, and summarize issues safely. Any write, apply, or destructive command should require explicit human approval.
5. What are custom skills in Claude Code?
Custom skills are predefined workflows, scripts, and rules that guide Claude’s operational behavior. They can include namespace rules, cluster checks, approved commands, and standardized output formats. These skills help reduce ambiguity and make troubleshooting more consistent.
6. What is the purpose of a CLAUDE.md file?
A CLAUDE.md file can document team conventions, naming rules, escalation steps, and safe operating procedures. Claude can use this information to follow organization-specific Kubernetes practices. This helps turn tribal knowledge into repeatable operational guidance.
7. How can Claude help with Kubernetes debugging?
Claude can help by checking node readiness, failed pods, events, logs, storage issues, and certificate risks. It can summarize noisy command outputs and suggest the next diagnostic step. This makes troubleshooting faster and less dependent on manually scanning endless terminal sludge.
8. What is a Kubernetes health check skill?
A Kubernetes health check skill is a reusable workflow that generates a structured status report for a cluster. It may check nodes, PVCs, failed jobs, scheduling pressure, certificates, and warning events. The output can classify the cluster as healthy, warning, or critical.
9. How does Claude assist with pod troubleshooting?
Claude can guide log collection using the correct namespace, container, and context. In CrashLoopBackOff cases, it can remind operators to check previous container logs. It can also summarize error patterns and likely causes from collected logs.
10. How does Claude help prevent wrong-cluster mistakes?
Claude-powered workflows can require validation of the active cluster, namespace, and environment before any action. This reduces the risk of running commands against production when the operator meant staging. It is a simple guardrail, which is apparently necessary because terminals all look equally innocent.
11. How does Claude support YAML validation?
Claude can review Kubernetes YAML files for configuration mistakes, invalid selectors, probe issues, and resource misconfiguration. It can compare the intended change with the actual manifest structure. This helps catch problems before they create incidents.
12. What YAML errors can Claude help identify?
Claude can help identify incorrect resource limits, missing requests, bad readiness probes, broken liveness probes, selector mismatches, and namespace errors. It can also flag risky drift between Helm values and rendered manifests. These checks reduce configuration-related outages.
13. What is a plan-first workflow?
A plan-first workflow previews infrastructure or configuration changes before applying them. Tools like OpenTofu can generate a tofu plan so teams can review the expected impact. Claude can help interpret the plan, but the final approval should remain with humans.
14. How does Claude support safer scaling decisions?
Claude can help analyze CPU, memory, I/O, HPA behavior, and external bottlenecks before recommending scaling changes. It may suggest right-sizing requests before simply increasing replicas. This avoids wasteful scaling decisions that make cloud bills grow like weeds.
15. How can Claude reduce Kubernetes operational costs?
Claude can reduce costs by summarizing command outputs, improving troubleshooting speed, and supporting right-sizing decisions. Token-efficient skills can also lower AI usage costs by avoiding raw command dumps. Better diagnosis means fewer unnecessary scaling actions and less wasted infrastructure.
16. Why is token efficiency important in Kubernetes AI workflows?
Token efficiency matters because repeated diagnostics across clusters can create significant API usage. Condensed outputs are cheaper and easier to interpret than long raw logs. This improves both cost control and operational clarity.
17. How does eBPF observability help Claude-driven workflows?
eBPF observability can monitor subprocess behavior and external calls made during Claude-assisted operations. This helps teams audit what the AI-driven workflow executes and how much overhead it creates. It also supports safer governance for AI agents running in operational environments.
18. What is Kubernetes hibernation for AI agents?
Kubernetes hibernation pauses idle AI agent workloads while preserving their state. This reduces compute waste while allowing agents to resume when needed. It is useful for large agent fleets where continuous runtime would be unnecessarily expensive.
19. How should teams start using Claude for Kubernetes operations?
Teams should begin with read-only diagnostics such as logs, events, health checks, and resource summaries. They can then document conventions in CLAUDE.md and add safe skills for common incidents. Write actions should come later through plan-first and approval-based workflows.
20. What is the future of Claude AI in Kubernetes operations?
Claude AI is likely to become more integrated with observability tools, skill registries, GitOps workflows, and infrastructure-as-code previews. Future systems may support stronger agent automation while keeping governance and verification central. The best results will come from disciplined workflows, not random prompting dressed up as platform engineering.
Related Articles
View All
Claude Ai
Deploying an MCP Server for Claude in Production: Docker, Kubernetes, Monitoring, and Scaling Guide
Learn how to deploy an MCP server for Claude in production using Docker and Kubernetes, with RBAC, observability, autoscaling, and safety controls.

Claude Ai
Designing Reliable Tools for an MCP Server for Claude: Schemas, Validation, and Error Handling
Learn reliable MCP tool design for Claude using precise schemas, strict validation, and LLM-friendly error payloads that enable self-correction and safer execution.

Claude Ai
Top Fable 5 Use Cases in Business: Operations to Support
Explore the top Fable 5 use cases in business, including software engineering, operations, marketing, customer support, and strategic planning.
Trending Articles
The Role of Blockchain in Ethical AI Development
How blockchain technology is being used to promote transparency and accountability in artificial intelligence systems.
What is AWS? A Beginner's Guide to Cloud Computing
Everything you need to know about Amazon Web Services, cloud computing fundamentals, and career opportunities.
How to Install Claude Code
Learn how to install Claude Code on macOS, Linux, and Windows using the native installer, plus verification, authentication, and troubleshooting tips.