
RAG vs CAG
The way AI systems use information is changing quickly. For the last few years, Retrieval Augmented Generation, known as RAG, has been the default method for helping language models access external knowledge. Now a second approach called Cache Augmented Generation, often referred to as CAG, is gaining attention. As companies explore practical automation, many professionals strengthen their fundamentals through programs like the AI Certification because understanding how these frameworks work is becoming essential. This shift is happening because models are getting longer context windows, more memory efficient architectures and better internal reasoning abilities. These upgrades make it possible for some tasks to avoid retrieval entirely and instead rely on cached information that the model can reuse.
What RAG Does and Why It Became Popular
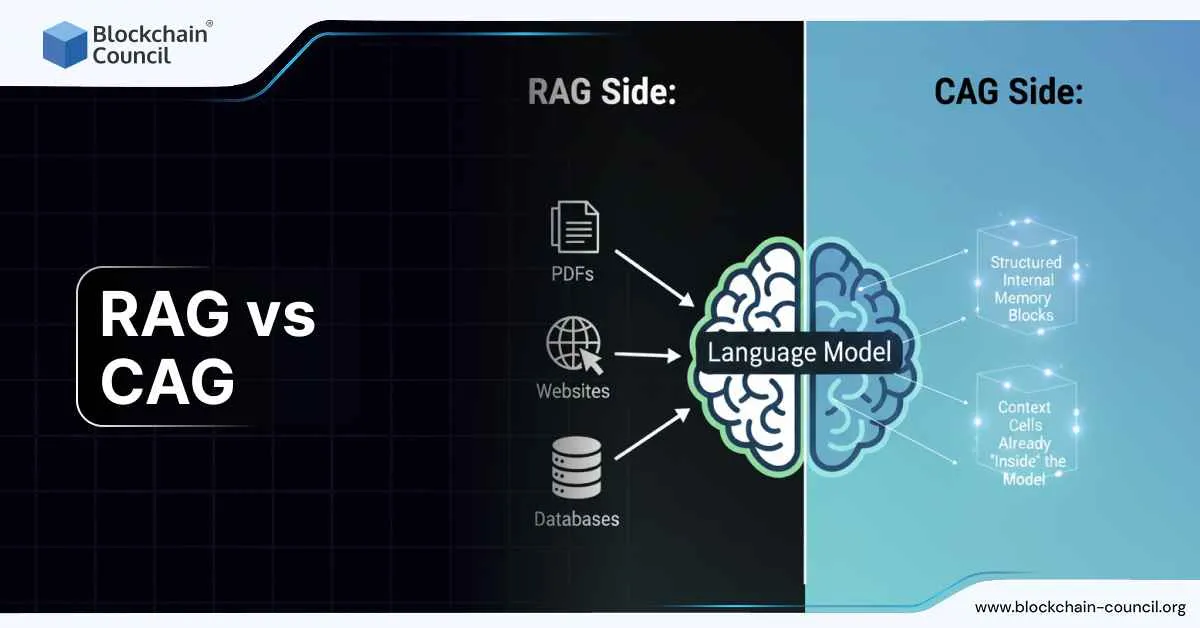
RAG became mainstream because it solved a basic limitation in language models. Earlier models did not know anything beyond their training data, and they could not update themselves with live information. RAG changed this by placing a retrieval step before model generation. When a user asks a question, the system searches for relevant documents, feeds those documents into the model and asks the model to answer using that context.

The main strength of RAG is that it can use large and constantly changing datasets. This makes it ideal for news updates, product documentation, research archives, analytics dashboards and any domain that evolves from day to day. As long as the retrieval system is well designed, RAG can ground the model’s answer in specific documents and reduce hallucinations.
However, RAG comes with friction. Retrieval adds delay. Vector databases need maintenance. Chunking strategies can break context. Poor retrieval choices can cause wrong answers even when the correct information exists. These issues are the reason people started looking for alternatives that simplify the entire pipeline.
Why CAG Is Becoming a Serious Contender
CAG approaches the problem differently. Instead of retrieving information at the moment of each query, CAG preloads important knowledge into the model’s context and stores the key value cache generated from that preload. When the user sends a prompt, the model does not need to read the entire corpus again. It simply reuses the cached internal memory and answers using that stored context.
This has two major advantages. First, latency drops significantly because the system processes fewer tokens. Second, the architecture becomes much simpler. You do not need vector databases, embedding pipelines or retrieval logic. Once the cache is built, the model behaves as if it has already read all the relevant information before the conversation began.
CAG is especially useful when the knowledge is stable. Internal policy manuals, compliance documents, company guidelines and technical playbooks rarely change. For these domains, preloading context once and reusing it many times can be more efficient than performing thousands of retrieval calls.
How the Two Methods Differ in Real Use
Freshness of information
RAG works best when content changes regularly. If a legal requirement, market trend or research summary updates, a RAG system can reflect the change immediately because retrieval happens at runtime. CAG works best when content remains stable, since updating the cache requires rebuilding it.
Scale of the knowledge base
RAG can handle millions of documents because it retrieves only a small portion each time. CAG is limited by the model’s context window and the memory capacity of the cache. Even with modern long context models, loading very large corpora is not practical.
Consistency of answers
CAG tends to produce more stable results because every answer draws from the same cached context. RAG can produce variation because the retrieved chunks change depending on the query wording.
System complexity
RAG requires embeddings, indexing, vector databases and retrieval logic. CAG requires none of that, but the cache regeneration step can be heavy when large updates occur.
Speed
CAG is usually faster at runtime because retrieval does not happen. RAG is slower because of the extra processing steps, especially with large corpora.
When RAG Is the Better Solution
RAG is the preferred choice when:
- The data changes frequently
- Users expect up to date answers
- The dataset is far larger than the model’s context window
- Source citation is important, such as in legal, research or compliance work
- The AI system must operate across many knowledge categories
RAG remains dominant for enterprise knowledge search, customer support on evolving products, research tools, financial assistants and analytic copilots.
Developers building RAG systems often strengthen technical fundamentals through structured programs such as the Tech Certification because setting up embeddings, vector stores and retrieval pipelines requires a clear understanding of architecture and data flow.
When CAG Becomes the Smarter Choice
CAG is best when:
- The knowledge base changes slowly
- You want predictable and consistent answers
- You want lower latency for user interactions
- You want to avoid the cost and complexity of managing retrieval pipelines
- The corpus fits into the model’s context at a manageable level
Teams use CAG heavily for policy assistants, onboarding chatbots, product documentation helpers and internal workflow copilots that rely on the same repeating information. It is also useful for mobile or lightweight applications where retrieval infrastructure would be too heavy.
Why Hybrid Systems Are Becoming Popular
The strongest systems today combine both methods. RAG handles the dynamic parts of the knowledge base, while CAG caches stable information. This hybrid pattern is also emerging in agentic workflows, where agents need both long term memory and real time search ability.
A typical hybrid setup might preload company policies into the cache while using retrieval to fetch new research papers, customer inquiries or live analytics. This delivers both stability and freshness.
What This Shift Means for Businesses
As AI adoption accelerates, companies need to choose which knowledge method powers their assistants, copilots and automation tools. Understanding the tradeoffs between RAG and CAG is now a core skill, not an optional technical detail. Many organisations exploring this decision also look at frameworks for team readiness and strategic implementation through resources like the Marketing and business certification, since the impact of these choices often extends into operations, customer experience and long term productivity.
Conclusion
RAG and CAG each solve similar problems but in very different ways. RAG is the flexible, scalable and up to date choice for large and dynamic datasets. CAG is the faster and simpler option for stable and structured knowledge. Together, they shape the next generation of AI systems that rely on both memory and search. Understanding when to use each method helps developers, teams and organisations build smarter and more efficient AI experiences as they move deeper into real world automation.


