AI Tool APE-Bench I Set to Test Automated Proof Engineering

APE-Bench I is a new benchmark designed to test how well AI models can handle real-world tasks in formal mathematics. Unlike traditional benchmarks that focus on isolated theorem proving, APE-Bench I emphasizes the iterative and complex nature of maintaining large formal math libraries. It introduces the concept of Automated Proof Engineering (APE), aiming to automate tasks like adding features, refactoring proofs, and fixing bugs using AI. This benchmark is built from over 10,000 real-world commits in Mathlib4, providing a realistic and challenging environment for evaluating AI capabilities in proof engineering.
What is APE-Bench I?
APE-Bench I is a benchmark that evaluates AI models on their ability to perform file-level edits in formal math libraries. Each task in the benchmark consists of:

- Instruction: A natural language description of the desired change.
- Pre-Edit File: The original Lean source code before the change.
- Patch: The edit that transforms the pre-edit file into the desired post-edit version.
These tasks are derived from actual edits in Mathlib4, ensuring they reflect real-world proof engineering challenges.
Key Features
Real-World Data
APE-Bench I is constructed from over 10,000 real-world commits in Mathlib4. Each task is based on actual developer activity, ensuring contextual relevance and authenticity.
Instruction-Driven Tasks
Each task includes a natural language instruction generated by an AI model, summarizing the intended edit in an imperative style. This approach aligns with how developers communicate changes and allows for evaluating AI models on their ability to follow instructions.
Two-Stage Evaluation
APE-Bench I employs a two-stage evaluation process:
- Syntactic Verification: Checks whether the edited file passes Lean’s type-checking.
- Semantic Judgement: Assesses whether the edit fulfills the instruction’s intent using an AI model as a judge.
This dual approach ensures both the correctness and relevance of the edits.
Scalable Infrastructure
To support scalable evaluation, APE-Bench I introduces Eleanstic, a version-aware Lean infrastructure that enables efficient, stateless patch validation across thousands of commits. Eleanstic allows for reproducible, parallelizable, and version-aware Lean verification.
How APE-Bench I Works
APE-Bench I’s task extraction pipeline proceeds in four stages:
- Commit Sourcing and Diff Decomposition: Mining Git commits and decomposing them into file-level diffs.
- Chunk-Level Expansion: Segmenting these diffs into semantically scoped chunks.
- Multi-Stage Filtering: Removing trivial or structurally incoherent edits based on semantic relevance, content quality, and structural integrity.
- Syntactic Validation: Compiling the remaining patches using Lean to ensure structural soundness.
Each task is paired with a natural language instruction generated by an AI model from the raw diff, summarizing the intended edit in an imperative style. A reverse validation procedure ensures semantic alignment between the instruction and the patch.
Evaluation and Results
APE-Bench I enables a comprehensive evaluation of leading AI models on realistic proof engineering tasks. Empirical results demonstrate strong performance on localized edits but substantial degradation on handling complex proof engineering. For instance, o3-mini leads by a wide margin, achieving nearly twice the semantic success rate of the next best model. However, most models degrade sharply as task size increases, highlighting the challenges in automating complex proof engineering tasks.
AI Model Performance As Per APE-Bench I
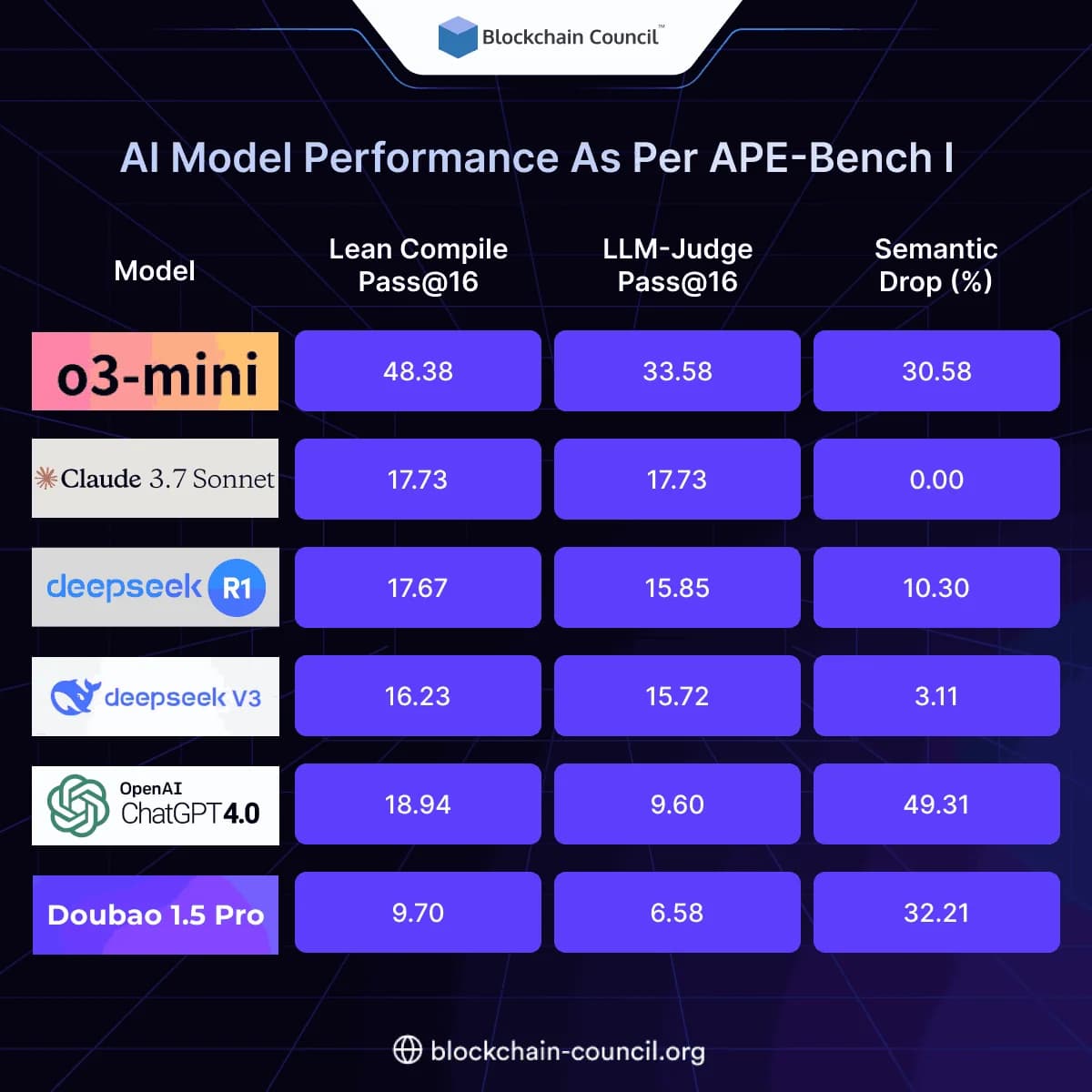
Semantic Drop is computed as the percentage of Lean-compilable outputs that fail LLM-based semantic validation.
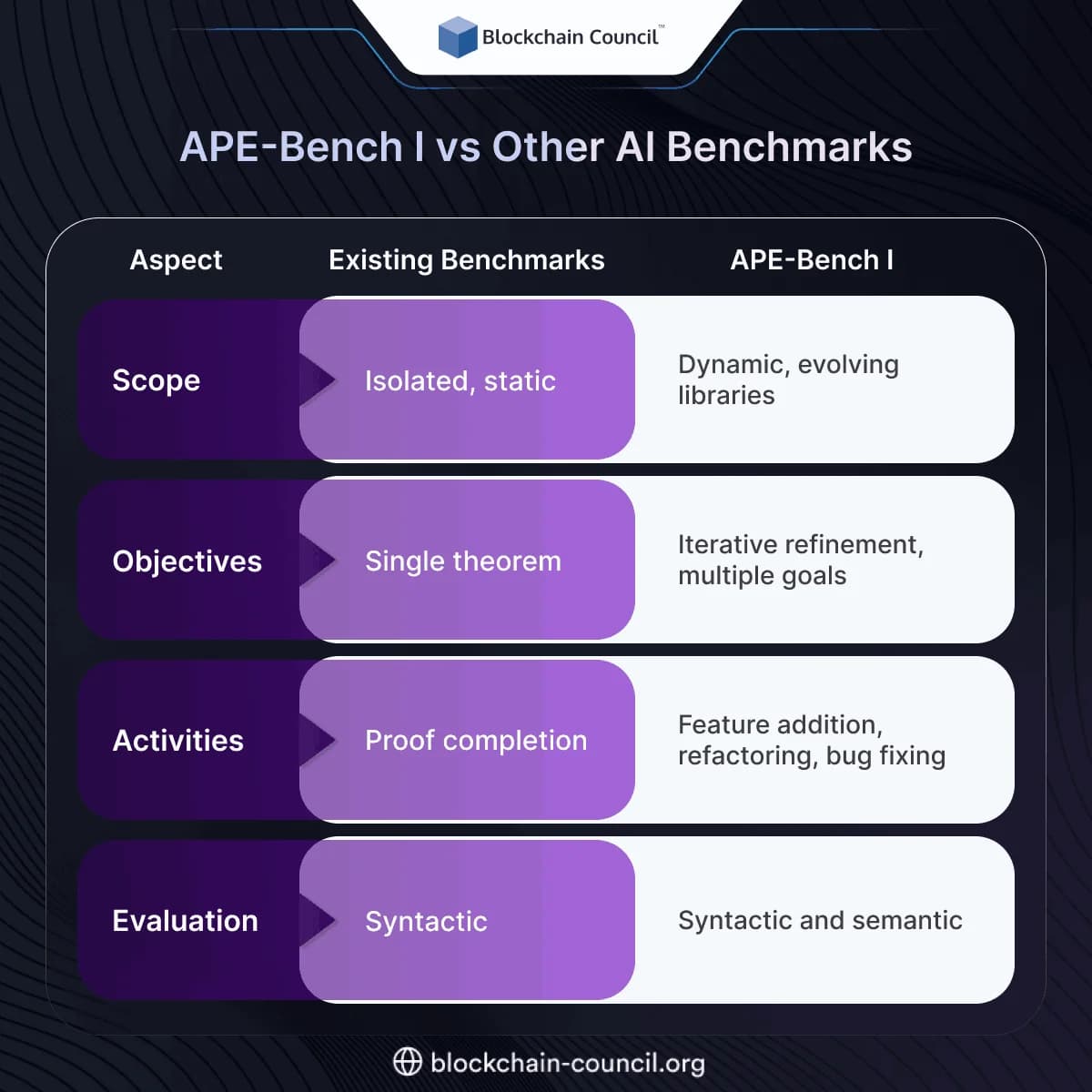
APE-Bench I vs Other AI Benchmarks
APE-Bench I addresses the limitations of existing theorem-proving benchmarks, which often focus on isolated, static proof tasks. By contrast, APE-Bench I captures the iterative, engineering-intensive workflows of real-world formal mathematics libraries.
Future Directions
APE-Bench I lays the foundation for developing agentic workflows in proof engineering. Future benchmarks aim to target multi-file coordination, project-scale verification, and autonomous agents capable of planning, editing, and repairing formal libraries. This progression reflects the increasing structural and semantic complexity of real-world proof engineering tasks.
Why It Matters
APE-Bench I isn’t just another benchmark. It’s designed to help developers and AI researchers alike understand where models excel—and where they struggle—when working on real-world proof engineering tasks. If you’re serious about AI or planning to expand your career with an AI Certification, this benchmark offers valuable insights into what skills are needed to thrive in this space.
For data enthusiasts, a Data Science Certification can also enhance your understanding of how to interpret these benchmark results. At the same time, a Marketing and Business Certification might help you strategize how to integrate AI into broader business workflows.
Conclusion
APE-Bench I represents a significant step forward in automating proof engineering tasks within formal mathematics libraries. By leveraging real-world data, instruction-driven tasks, and a robust evaluation protocol, it provides a realistic and controlled setting for evaluating proof engineering capabilities. As the field progresses, APE-Bench I will serve as a valuable resource for researchers and developers aiming to advance the capabilities of automated proof engineering.
Related Articles
View All
AI & ML
How Prompt, Loop, and Context Engineering Shape Reliable AI Agents
Learn how prompt, loop, and context engineering improve AI agent reliability, enterprise GenAI workflows, orchestration, guardrails, and governance.

AI & ML
Prompt Engineering vs Loop Engineering vs Context Engineering: Key Differences for AI Developers
Learn how prompt engineering, context engineering, and loop engineering differ, where each fits, and why production AI needs all three layers.

AI & ML
Building an AI Video Pipeline for Marketing Teams: Script to Automated Editing and Localization
Learn how to build an AI-first marketing video pipeline, from strategy and script generation to automated editing, repurposing, and localization with human review checkpoints.
Trending Articles
The Role of Blockchain in Ethical AI Development
How blockchain technology is being used to promote transparency and accountability in artificial intelligence systems.
AWS Career Roadmap
A step-by-step guide to building a successful career in Amazon Web Services cloud computing.

Can DeFi 2.0 Bridge the Gap Between Traditional and Decentralized Finance?
The next generation of DeFi protocols aims to connect traditional banking with decentralized finance ecosystems.